データサイエンス、何ができる?データサイエンティストとは

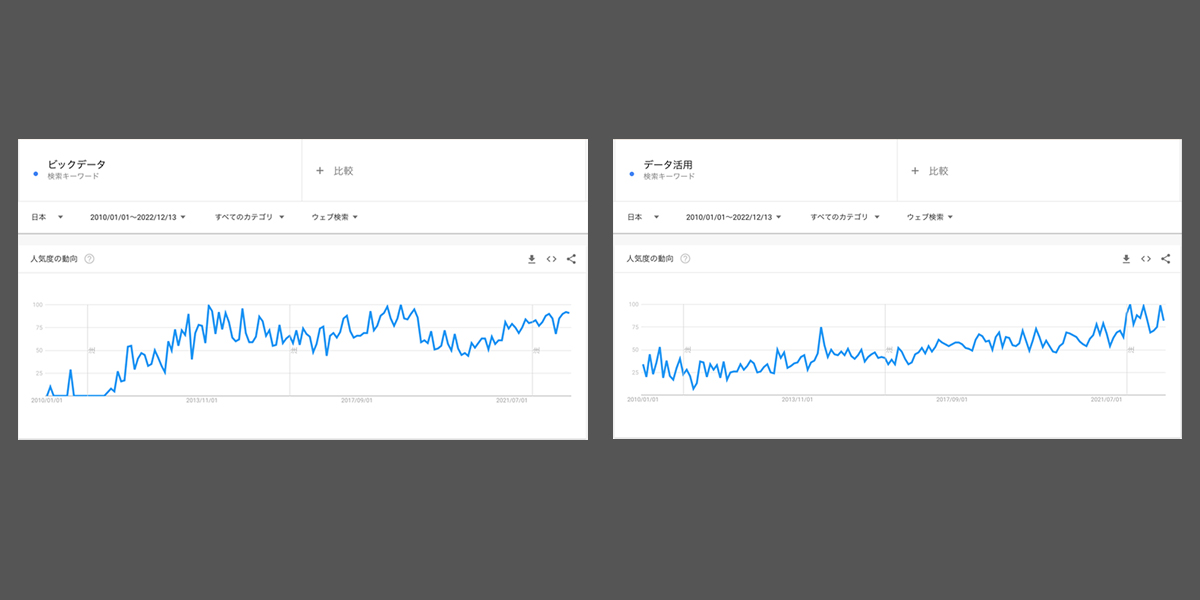
2010年代以降、ビックデータやAIが一つのトレンドとなり、ビジネスの現場でもデータサイエンスに関わる担当者が増えていきました。 下記は「データ活用」「ビックデータ」の検索ボリューの推移になります。2010年から現在におけるまで徐々に上がってきていることがわかります。
データサイエンスは、企業において、「売上を伸ばす」「コストを下げる」「リスクを下げる」など、データを活用して何かしらの意味のあることを見出すために活用されています。
こういったデータを活用したり、デジタル化を行ったりする企業の動きはDX(デジタルトランスフォーメーション)とも言われ、さまざまな企業がDXに取り組めるようになりました。 DXが可能になった背景には、企業は膨大な量のデータを抱えていることに気づいたことに加え、高速処理や機械学習の進化などが挙げられます。
従来では困難であったDXは、今日では企業の差別化にもなっています。
データサイエンスとは
これまでデータサイエンスが注目されていて、ビジネスにも活用され始めていることをお伝えしてきましたが、データサイエンスとは何なのでしょうか。データサイエンスは誰でも簡単に明日からできるものなのでしょうか。
データサイエンスとは何か?
データサイエンスとは何であるか。Wikipediaをはじめ、どのような説明がされているのか調べてみました。
Wikipediaでは、データサイエンスを情報科学、統計学、アルゴリズムを横断的に扱う学問として紹介されています。
データサイエンス(英: data science、略称: DS)またはデータ科学とは、データを用いて新たな科学的および社会に有益な知見を引き出そうとするアプローチのことであり、その中でデータを扱う手法である情報科学、統計学、アルゴリズムなどを横断的に扱う。 (Wikipedia)
マイクロソフトリサーチに所属していたチューリング賞を受賞した米国の計算機科学者ジム・グレイ (Jim Gray)は、データサイエンスを科学的探究の「第4のパラダイム」と提唱しています。
data science as the "fourth paradigm" of science (Turing award winner Jim Gray)
スタンフォード大学の統計学者であるデヴィッド・ドノホ(David Donoho )によると、ビックデータが統計とデータサイエンスが分ける基準ではないと言っています。
“Big data” is not a credible criterion for meaningful distinction between statistics and data science, for both historical and scientific reasons (David Donoho)
AWSでは、データサイエンスについて、下記のように記載しています。
データサイエンスは、ビジネスにとって意味のあるインサイトを抽出するためのデータの研究です。これは、数学、統計、人工知能、コンピュータエンジニアリングの分野の原則と実践を組み合わせて、大量のデータを分析する学際的なアプローチです。この分析は、データサイエンティストが、何が起こったのか、なぜ起こったのか、何が起こるのか、結果で何ができるのかなどの問題を提起し、答えるのに役立ちます。
(AWS)
Oracleでは、下記のように記載しています。
データ・サイエンスは、まだ新しい学術分野です。元々は、統計分析とデータ・マイニングの分野から発展したものです
(Oracle)
データサイエンス、もしくはデータ科学は、明確な定義はないが、新しい学問であり、統計学とデータ・マイニングの知識が必要であることがわかります。
一般的には、データサイエンスが学問であるという認識もされていないでしょう。
「誰でもデータの分析くらいできるでしょ。」と考えている方も多いのが現実ではないでしょうか。しかし、データサイエンスを実際のビジネスに応用していくには、非エンジニアであってもプロジェクトマネージャーは業務への知識とベーシックな基礎知識は必要になってきます。知識の重要性に対する認識をし、外部リソースや専門家と協力し、適切な体制を築くことが重要になってくるでしょう。
データサイエンスのできること
データ サイエンスの分野は定義が難しいことで有名です。さまざまな捉え方があるので、3つほど紹介します。
比較・抽出・分類・予測
データサイエンスのできることは、主に「データを比較する」「データから要点を抽出する」「データを分類する」「データから予測する」の4つに大別できると考えています。
データを比較する
収集したデータを比較し、特徴を捉えます。 (例)事業の売上実績と予算目標、WebページのABテスト
データから要点を抽出する
収集した大量のデータから、同時に発生するなど、相関関係を探索・抽出します。 (例)ビールの売上に対しての湿度、気温、広告の関係性を捉える
データを分類する
収集した顧客や商品などに関するデータを、特徴に応じて分類します。 (例)ワインの等級を分類、勘定科目の仕訳
データから予測する
収集したデータから、受注、購入といった特定の事象が発生する確率および、その発生要因を明確にします。 (例)購入確率によってレコメンドする、コロナ感染症の患者数を予測する
基本的には、「データを比較する」「データから要点を抽出する」「データを分類する」「データから予測する」の4つのことが可能です。
技術的な難易度とデータサイエンスにできることの関係
よりビジネスサイドに理解していただくには、下記の難易度の順に並べたピラミッド型の図がわかりやすいかもしれません。日本では、三好大悟『ビジネスの現場で使えるAI&データサイエンスの全知識』を参考に営業資料等を展開している企業も多いのか、よく似ているようなことが書かれています。ピラミッドの上になるほど、難易度がどんどん上がっていきます。
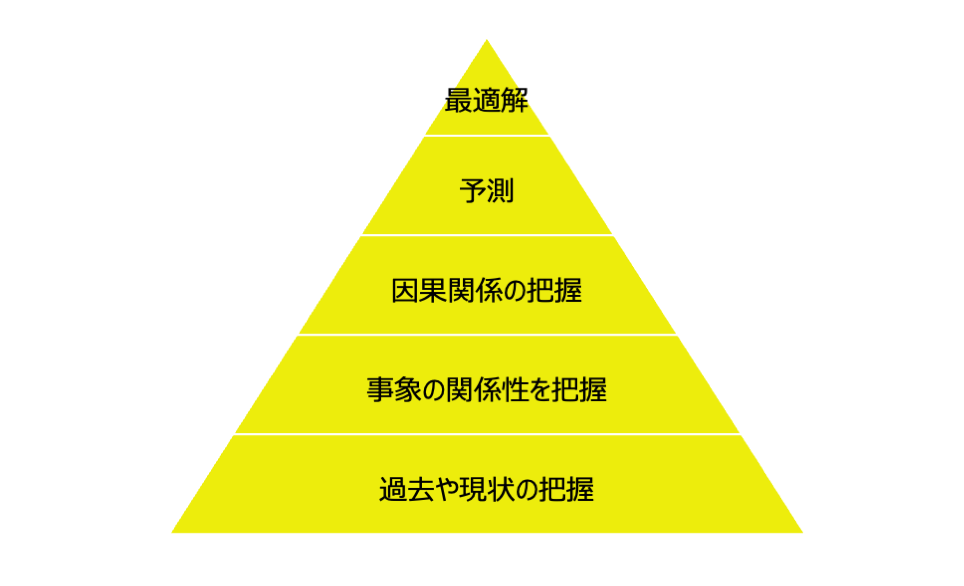
「過去や現状の把握」「事象の関係性を把握」「因果関係の把握」「将来の予測」「意思決定の最適化」を行うことができます。実際の作業ではどのような手法が取られるのか、概要を紹介します。
過去や現状の把握
主に下記の技術を活用します。
集計・ 可視化
統計学/記述統計
人工知能/教師なし学習
過去のデータから事実を捉えることができます。教師なし学習では、過去データの関係性の定量把握(クラスタリングなど)。 どんなグラフを使い、どんな計算手法を選択するかで、データ把握の精度に差がついてきます。一見、誰にでもできそうですが、ベーシックな知識やスキルは必要になってくるでしょう。
事象の関係性を把握
主に下記の技術を活用します。
集計・ 可視化
統計学/記述統計、推計統計
人工知能/教師なし学習
手元データを集計、手元データから全体のデータを読み解きます。
因果関係の把握
主に下記の技術を活用します。
集計・ 可視化
統計学/記述統計、推計統計、時系列分析
人工知能/教師あり学習
データから傾向を読み解きます。時系列の要素を加味し、将来情報を読み解きます。
将来の予測
主に下記の技術を活用します。
集計・ 可視化
統計学/記述統計、推計統計、時系列分析
人工知能/レコメンデーション、教師あり学習
どのようなメカニズムで予測できるかを検討します。レコメンデーションではユーザの好みと推測される情報を提案します。
意思決定の最適化
主に下記の技術を活用します。
集計・ 可視化
統計学/記述統計、推計統計、時系列分析
人工知能/レコメンデーション。教師あり学習。数理的最適化。
対象となる変数を変えたときに、 どのような変数の値にすれば、 目標値が最大化/最小化するかを 算出する。
AI(人口知能)、機械学習、深層学習(ディープラーニング)との関係
技術的な概要に人工知能と記載しましたが、人工知能と何か。人によって解釈が違うことが多くあります。 人工知能の一分野として機械学習があり、機械学習の一手法として深層学習があります。近年の深層学習の発展や成果が著しいため「人工知能≒機械学習≒深層学習」のように語られる場面が多くなっています。
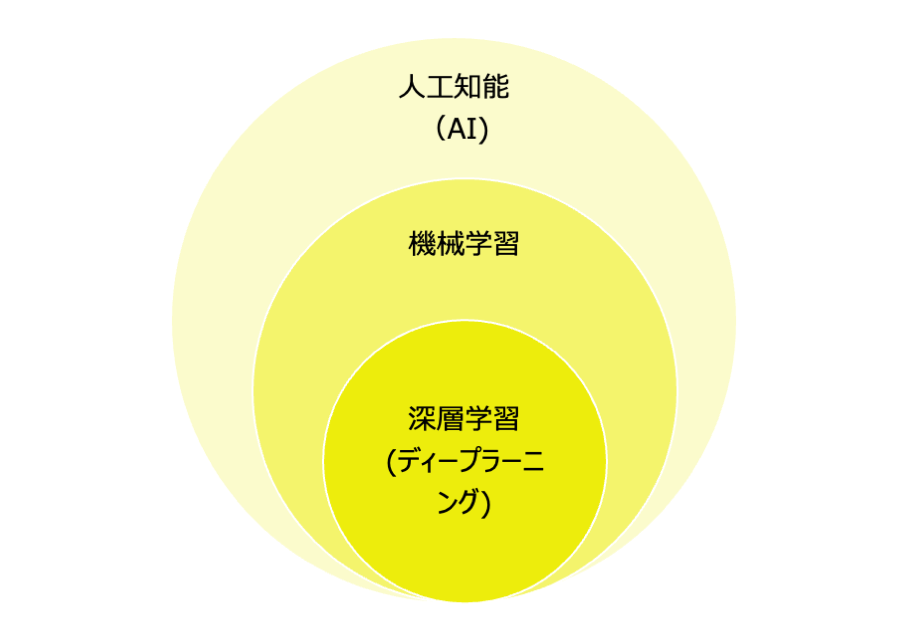
「人工知能(AI)>機械学習>深層学習(ディープラーニング)」の関係性だけはしっかり抑えておきましょう。
データサイエンスのプロセスから定義
データ サイエンスの分野は定義が難しいことで有名ですが、スタンフォード大学の統計学者である David Donoho による Greater Data Science (GDS) の定義であるDavid Donoho’s Six-Part Definitionでは、データサイエンスのプロセスから考察した下記の6つの分野があると提唱されています。
データの探索と準備
データ表現と変換
データ分析の実装
データの視覚化と表示
データモデリング
データサイエンスに関する科学(意志決定)
現場で実践する人にとっては常識のように思えます。しかし、データ サイエンスに関連する作業の複雑さは、この定義によって提供される明確さに到達することは容易ではなかったことでしょう。
データサイエンスの用いたれる言語
データサイエンスで利用されるプログラミング言語は「Python」と「R言語」です。Pythonは、汎用性が高いプログラミング言語で機械学習やAI開発といった分野で利用され、近年注目を集めています。 2010年代初頭、企業は膨大な量のデータを抱えていることに気づき、従来のビジネス分析ツールよりも優れたパフォーマンスと分析を提供する科学的な処理が可能である Python ツールの採用を開始しました。この「ビッグデータ」時代において、Python は企業がかつてない規模でデータ分析を行うことを可能にしました。
データサイエンス 身近な例
みなさんも企業で、クロス集計や二軸の可視化を日常的に行なっているでしょう。クロス集計や二軸の可視化はデータサイエンスの超初歩と言えます。
ポアソン回帰やロジスティック回帰などは統計モデリングの初歩的手法です。 下記はモデリングのステップですが、どんどんモデリングが複雑になってきます。実際のビジネスシーンで何が使われるのかというと、一般化線形モデルまでではないでしょうか。
線形モデル(単回帰分析)
一般線形モデル(重回帰分析など)
一般化線形モデル(ポアソン回帰・ロジスティック回帰など)
一般化線形混合モデル
階層ベイズ
他にも、機械学習ライブラリを活用したモデルの構築(SVM、決定木、ニューラルネットワーク、LDA、word2vec)があります。
入力するデータとデータ分析の目的によって、使われる手法は異なってきます。どの手法が適切なのかを判断することも含めて、データサイエンスと言えます。
データサイエンス活用事例
データサイエンスのプロジェクトは、実際にはビジネス現場でスタートを切ること自体が難しいのではないでしょうか。やりたいことが漠然としていたり、何ができるかわからなかったり、やりたいことが関係者間で統一できなかったり、経営層と会話が成り立たなかったり…様々な障壁があるでしょう。これはデータサイエンスだけでなく、新しいことに対して、よく起こる反応と言えるでしょう。
ここでは、何ができるのか紹介します。みなさんのビジネスで何が使えるかヒントに少しでもしていただけば幸いです。
回帰による予測
関係性を同時に満たす計算式を機械がデータから学習することで、複雑な予測が可能になります。
店舗の商品売上予測/コールセンターの入電数予測/店舗の来客予測/農作物の生産予測
分類による予測
確率の算出を行い、カテゴリーを予測します。
病状診断/試験薬の効果予測/見込顧客の絞り込み
時系列予測
変化を可視化し、幅広い分野や領域で活用できます。
電力の需要予測/商品の在庫予測
画像処理
画像処理がAIブームの立役者でもありました。非構造化データをデータとして処理できるという文脈でメディアを賑やかせていました。
医療診断/異常品検知/手書き書類の文字認識/顔認証
自然言語処理
画像処理の次の注目を集めたのが自然言語処理でした。
感情分析/類似判定/機械翻訳/文章要約
音声処理
音声処理は自然言語処理と密接な関わりがあります。
議事録作成/チャットボット/感情属性
クラスタリング
マーケティングではよく活用されます。
グループ分け/ユーザー属性
レコメンド
レコメンドはECサイトでよく活用されています。
商品の推薦
強化学習
機械がデータを収集して学習していきます。
ゲームやロボット
マーケティング部門でのデータサイエンス活用事例
マーケティング業務はデジタル化が進み、今までの顧客データやビックデータなどを組み合わせて、データに基づくマーケティング、すなわちデータドリブン・マーケティングにシフトすることが推奨されはじめています。例えば、データ駆動型のマーケティングを行うことで、潜在顧客が何を買うか過去の購入に基づき予測できるようになります。 それによって、パーソナライズされたマーケティング活動、つまり「セグメント オブ ワン」が行うことができるようになるでしょう。 一時期、one to oneマーケティングがもてはやされ時期がありますが、それが進化してリバイバルされたのが今日の「セグメント オブ ワン」と言えるでしょう。行き着くところまで行き着くと、セグメントは個人になる。
さらに、マーケティング戦略においては予測マーケティングを行うことで、対応を先回りできる可能性があると考えられています。 製品管理、顧客管理、ブランド管理において統合したデータ管理を行うことで、様々な予測を行うことが可能になるでしょう。
Netflixでは、運用および財務の観点から映画制作を最適化するために分析を使用していることです。 Netflixは分析を使用して、アプリでのユーザー エクスペリエンスから撮影現場のロジスティクスまで、すべてを最適化しています。たとえば、ある場所と別の場所での撮影の予測コストを予測するアルゴリズムを開発しました。また、アナリティクスを使用して、ボトルネックを減らし、ワークフローを合理化することで、編集などの撮影やポストプロダクション活動の効率を高めています。
マーケティング部門で活用事例の紹介は「マーケティングにデータサイエンスを活用したユースケースTOP10」で紹介しています。





