人事部門でのデータ活用:従業員の離職に関する分析~AI、機械学習による分析~

前回の記事「人事部門でのデータ活用:従業員の離職に関する分析~事前準備と基本的な分析~」では、データ概要の理解やデータ分析の目標設定の後、人間的な感覚に基づいて基本的な分析を行いました。 今回は、AI、機械学習の活用によるデータ分析法を取り入れてみます。 この記事では、AI、機械学習を使った手法が、前回紹介したような人間的な知識や経験を使った分析法とどのように異なるのか、その雰囲気を感じてもらいたいと思います。今回も難しい数学的な説明は避け、各手法や分析の流れのイメージを伝えることを優先しています。
データの概要
使用したデータは、「kaggle」から入手できる人事データです。このデータセットは、IBMのデータサイエンティストが作成した架空のデータであり、実在の人物に関わるデータ、ビジネス上の機密に該当するものではありません。
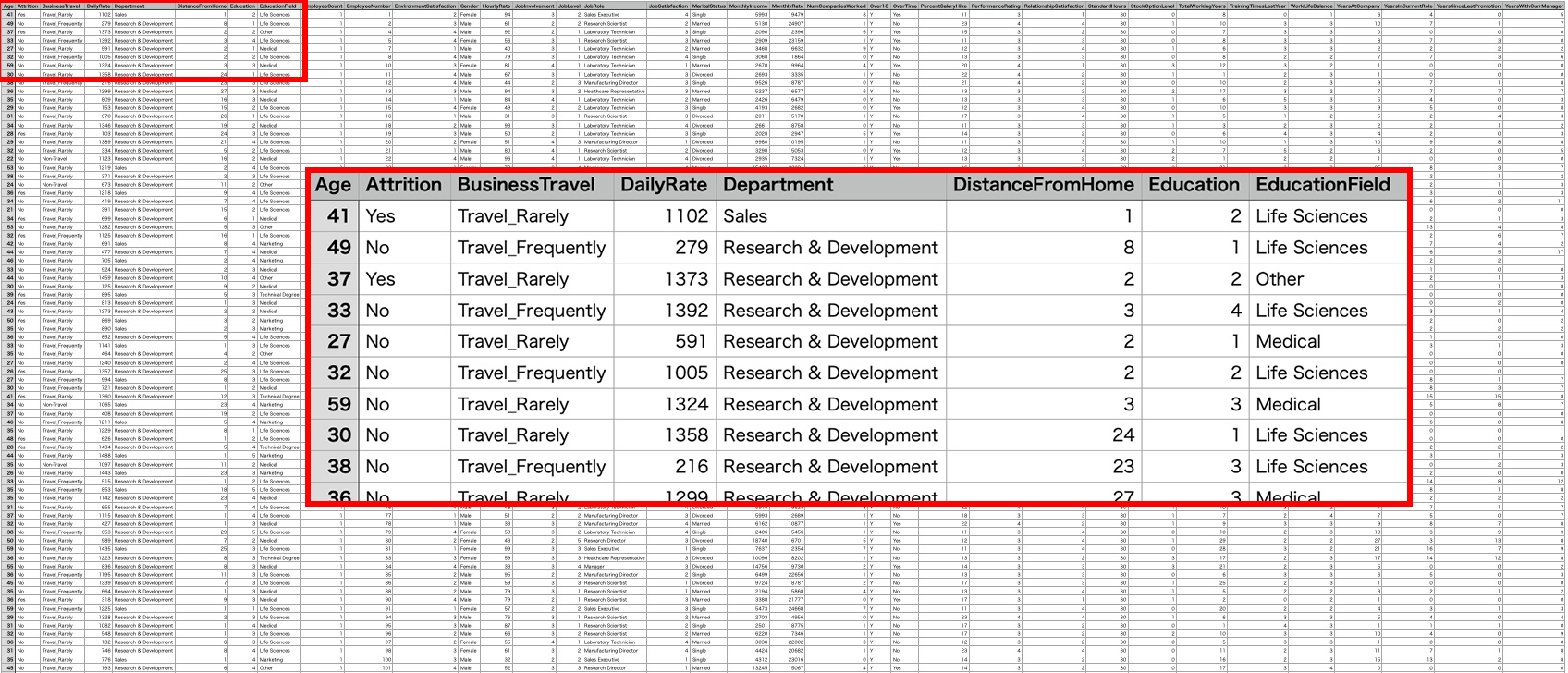
データ(csvファイル)のダウンロードはこちらから 従業員が離職者か非離職者かを示す情報に加えて、年齢や収入など35の要素について1470例のデータが含まれます。従業員が離職者か非離職者かを示す情報及び離職に関する分析には役立たない要素を除いたところ、以下の表のような構成になりました。
1 | Age | 年齢 |
2 | BusinessTravel | 出張の頻度 |
3 | DailyRate | 日給レート |
4 | Department | 所属部署 |
5 | DistanceFromHome | 自宅ー職場間の距離 (マイル) |
6 | Education | 教育レベル(学歴) |
7 | EducationField | 学生時代の専門分野 |
8 | EnvironmentSatisfaction | 環境への満足度(4段階) |
9 | Gender | ジェンダー |
10 | HourlyRate | 時給レート |
11 | JobInvolvement | 仕事への関与のレベル(4段階) |
12 | JobLevel | 仕事のレベル(5段階) |
13 | JobRole | 仕事上の役割(職種、役職) |
14 | JobSatisfaction | 仕事への満足度(4段階) |
15 | MaritalStatus | 婚姻の状況 |
16 | MonthlyIncome | 月収 |
17 | MonthlyRate | 月収レート |
18 | NumCompaniesWorked | これまでに勤務した企業数 |
19 | OverTime | 残業の有無 |
20 | PercentSalaryHike | 昇給率 |
21 | PerformanceRating | パフォーマンスレート(4段階) |
22 | RelationshipSatisfaction | 人間関係への満足度(4段階) |
23 | StockOptionLevel | ストックオプションレベル |
24 | TotalWorkingYears | トータルの勤続年数 |
25 | TrainingTimesLastYear | 過去1年間のトレーニング受講時間 |
26 | WorkLifeBalance | ワークライフバランス(従業員の実感、4段階) |
27 | YearsAtCompany | この会社での勤続年数 |
28 | YearsInCurrentRole | 現在の役職についてからの年数 |
29 | YearsSinceLastPromotion | 最後の昇進からの年数 |
30 | YearsWithCurrManager | 現在のマネージャーになってからの年数 |
データ分析のプロセスと前回のデータ分析を振り返り
体系的なプロセス
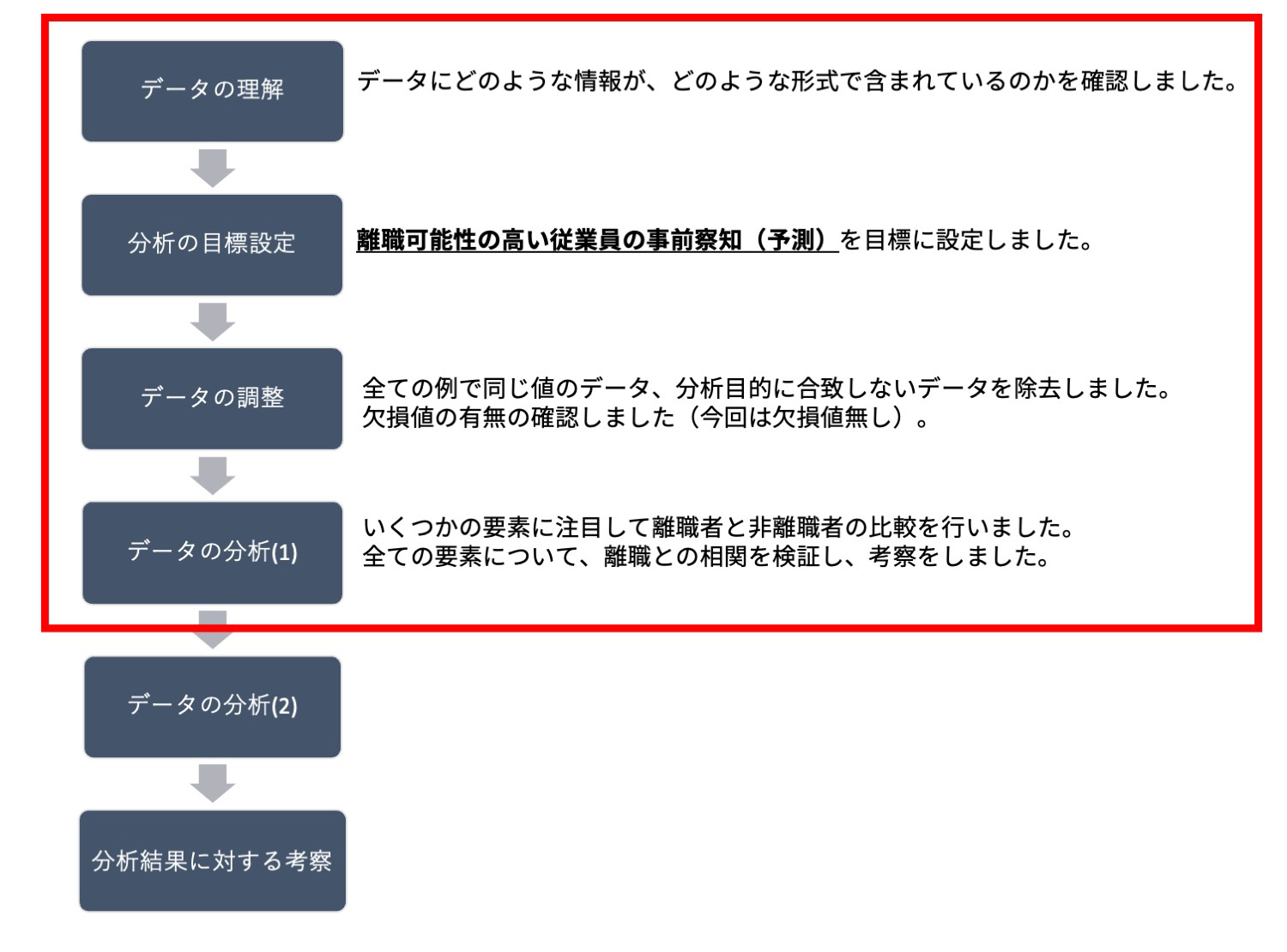
データ分析を体系化すると「データの理解→分析の目標設定→データの調整→データ分析(複数回)→分析結果に対する考察」という流れになります。前回はデータの分析の一回目まで行いました。
データ分析の目標設定
離職者と非離職者のデータから、従業員の離職にとって重要な意味を持つ要素の発見や、離職可能性の高い従業員の事前察知(予測)を目指します。
データの分析プロセス
データの分析は分析ごとにプロセスを踏みます。最初のデータ分析では、特徴の把握を行い、離職と要素との関係性を確認しました。
前回までの分析結果
年齢や収入など30の要素のうち、一般的に離職との関連性が強いと考えられているものについてデータを可視化してみました。その結果、大まかには予想された傾向が見られるものの、離職の原因となる単一の要素を見つけることは難しそうなことがわかりました。また、各要素と離職の間の相関は、いずれも非常に弱いものでした。
今回のデータ分析(2)での目標設定
分析戦略の再検討
データ分析によって有益な情報を引き出すためには、分析と結果の検討を繰り返しながら、効果的な分析方法を探索していく必要があります。前回までの分析結果を検討して、次にどのような分析を行うべきかを検討してみます。
前回の問題点
前回の分析は、「従業員の離職には原因があり、データに含まれる30の要素のいずれかがその原因である、もしくは要素のいずれかが原因と密接に関連している」ということを期待して実施されました。しかし、実際には30の要素のいずれも、要素単体で離職を説明することは困難です。
また、離職に至るルートが複数ある可能性も十分に考慮できていません。例えば、「優秀な人から辞めていく」傾向と「極端にパフォーマンスが劣る従業員は辞める」傾向が同時に観察される組織も多いのではないでしょうか。
仮説の改良
従業員が離職する原因はいくつかの要素が絡み合って生じる、と仮定します。また、離職に至るルートも一つではないと考えます。
データの分析(2)の目標設定

AI、機械学習の導入
改良した仮説を検証するためには、30の要素とその組み合わせを考慮する必要があり、前回行ったようなグラフ化をして検討する方法では、莫大な手間がかかります。 そこで、結果(今回は離職の有無)と多数の要素の関連を総合的に検討できる方法が望まれます。
AIを導入すると、このような人間には難しい複雑な判断を高速かつ高精度に実現できる可能性があります。AIのうち、データの特徴からそのデータの背景にある法則を把握する方法として「機械学習」があります。例えば、機械学習では離職者のデータと非離職者のデータの間の傾向の違いから、離職者と非離職者を見分ける法則を見出せる可能性があります。
AI、機械学習を用いた分析
AI、機械学習には様々な方法が含まれます。この記事では、ランダムフォレスト、サポートベクターマシン(SVM)という方法を使います。
分析結果の評価方法
ほぼ全てのケースでAI、機械学習を用いた分析結果は、完全、完璧なものではありません。常に間違いを含む可能性を認識し、分析結果の評価を行う必要があります。
具体的な評価手法としては、非離職者と離職者をそれぞれ正確に予測できるかという視点で、次の表の値を算出します。
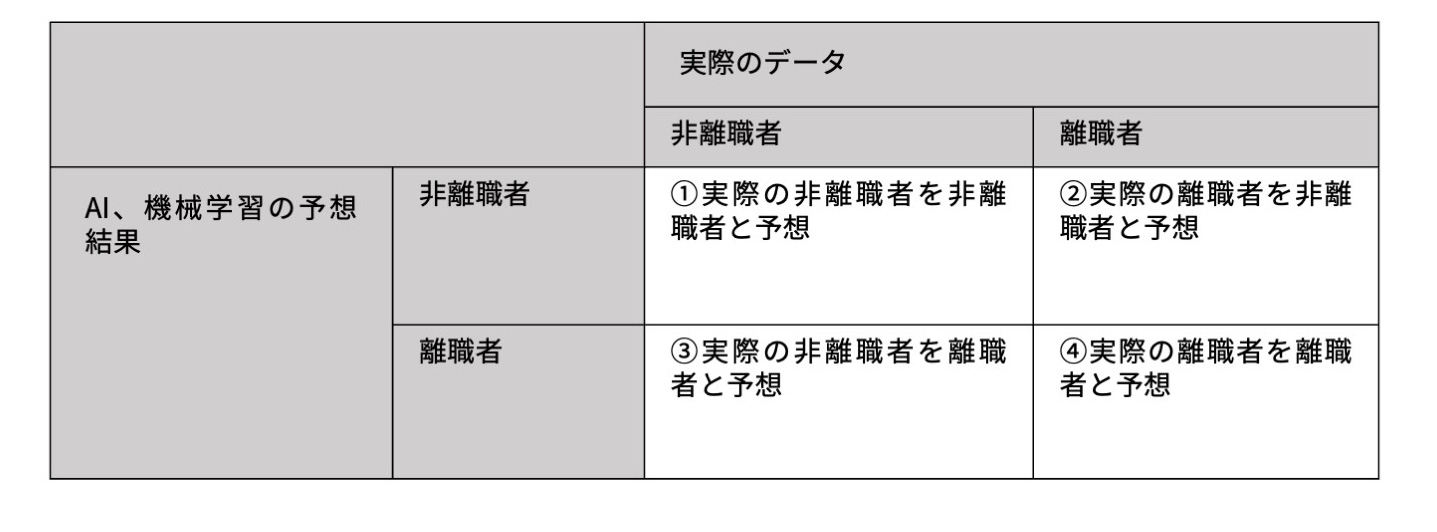
機械学習では、①~④の値を使った「適合率」「再現率」という指標が使われることがあります。
適合率/適合率は、AIが〇と予想したものの中に、実際に〇のデータがどれぐらいの割合を占めているかという指標です。離職者を予想する課題における適合率とは、④を③+④で割ったものが該当します。非離職者を予想する課題では、①を①+②で割ったものです。
再現率/再現率は、実際に〇のデータのうち、どのぐらいの割合をAIが〇と予想できたかを示す値です。離職者を予想する課題における再現率は、④を②+④で割ったものです。非離職者を予想する課題では、①を①+③で割ったものです。
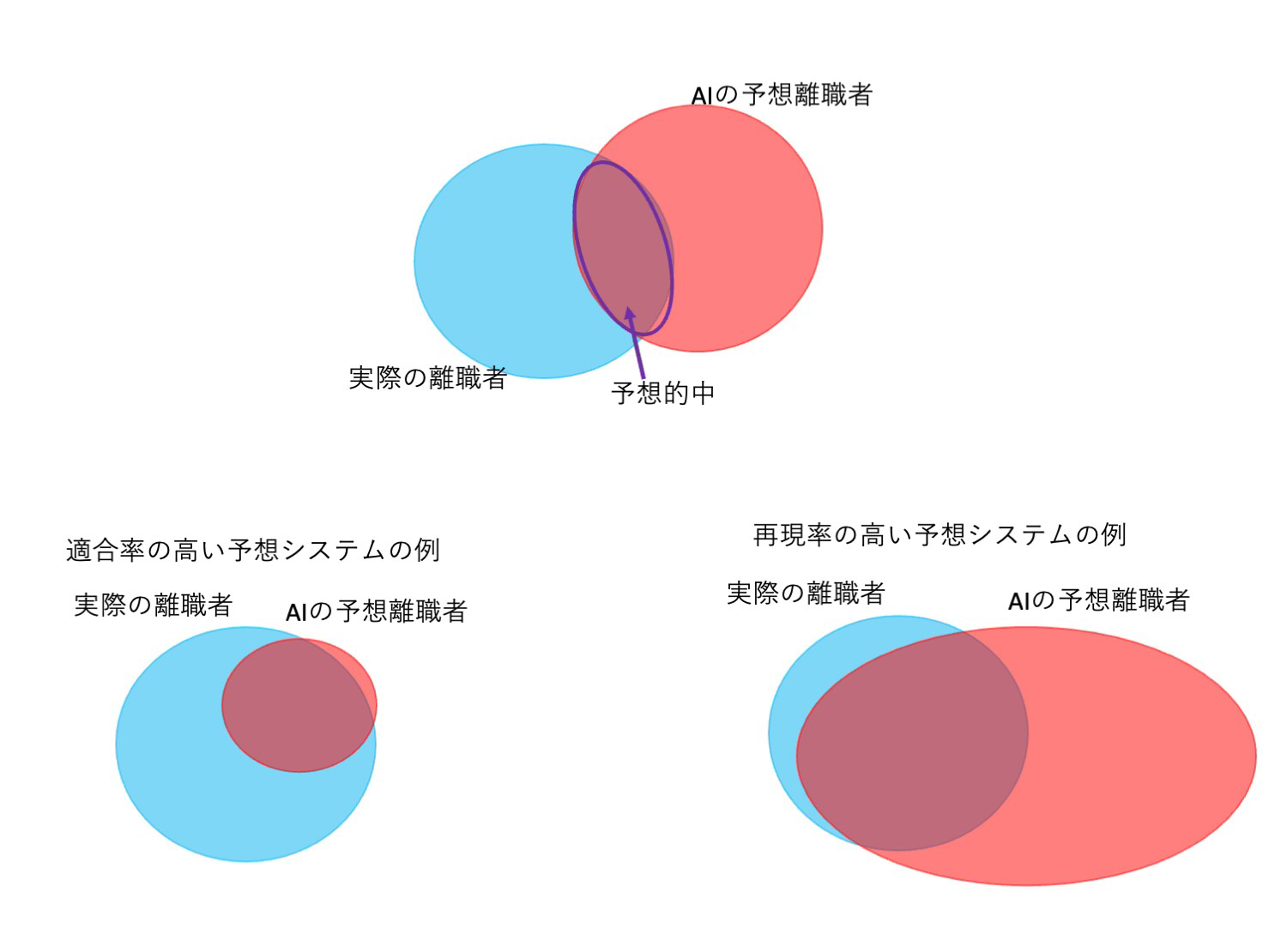
F値/適合率は「AIが間違えないこと」、再現率は「AIが見逃さないこと」の指標で、この両者はトレードオフの関係にあります。間違えないように慎重な判断基準を置けば見逃す確率が上がりますし、反対に見逃さないように基準を緩く設定すれば誤った判断をする確率が上がります。そこで、この両者のバランスを評価する指標としてF値という指標を用います。
この記事では、次の式で算出したF値(F1-Score)を用います。
F値 = 2 × 適合率 × 再現率 ÷ (適合率+再現率)
適合率または再現率のどちらかを重視したい事情がある場合には、適合率と再現率の値に重みづけした上でF値を算出することもあります。
データの下処理
機械学習をする前に、データの形状や値を調整する処理を行います。
量的データと質的データ(カテゴリカル変数)
データ中の要素には、年齢や収入のようにその量が数値で表されるもの(量的データ)と、所属部署や専門分野のような非数値的な情報(質的データ)が含まれています。非数値的な情報であっても、営業部=1、人事部=2、研究開発部=3のように数値に置き換えること自体は可能です。しかし、分析上、それら置き換えた数字を年齢や収入の数値と同じように取り扱うことは適切ではありません。
今回は、質的データを次のように変形します(One-hotエンコーディング)。下記のような
「性別」(男 or 女) → 「男であるか」(0 or 1)と「女であるか」(0 or 1)
「部署」(人事、研究開発、営業) → 「人事であるか」(0 or 1)、「研究開発であるか」(0 or 1)、「営業であるか」(0 or 1)
量的データのスケール調整
量的データの中には集団中の割合を意味する値のように0~1に収まるものや、年収のように大きな数字になるものもあります。これらのスケールの違いが機械学習の過程で問題になることがあるため、各要素においてスケールを調整し、要素間で値の範囲が大きく異ならないようにします。
学習用のデータと評価用データ
目的は未知のデータに対して正しい判断ができるかどうかを評価することなので、1470例のデータは学習用の1176例と評価用294例(学習用80%、評価用20%)に分割しました。1176例から見出される法則によって、未知の294例を正しく判断できるかが試されます。
データの分析〜AI、機械学習の実施〜
ランダムフォレスト
ランダムフォレストは、決定木という方法を多数組み合わせて判定する方法です。決定木は、A or Bのような条件分岐を繰り返して、元のデータから分類や回帰を行うことができます。いくつもの条件分岐を図にしたときに木のような構図になるため決定木という名前がついています。
ランダムフォレストでは、決定木を多数用意し、それらの判断のアンサンブルによって最終的な判断を定めます。多数の要素が含まれるデータでも手軽に分析できる強みがあります。
ランダムフォレストによる予測結果
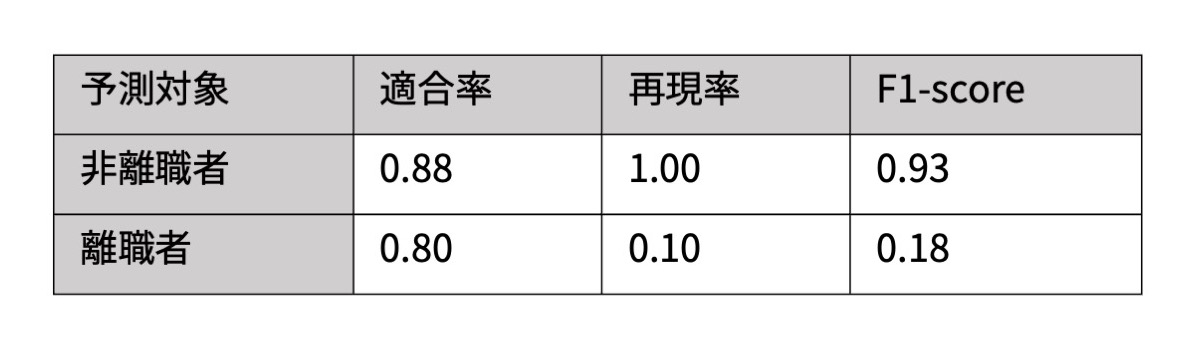
この結果を見ると、非離職者に対する予測が良好に行われている一方で、離職者に対する予測の再現率が低くなっています。離職者と予想した場合は実際に離職者である確率が高いものの、離職者を見逃しやすいと評価できます。
サポートベクターマシン(SVM)
サポートベクターマシンという手法によって、(厳密な定義はともかく)データのグループの間に境界線を見つけることができます。例えば、データ点がプロットされたグラフ上に線を引いて、離職者が多いエリアと非離職者の多いエリアを区分するようなイメージです。
サポートベクターマシンによる予測結果
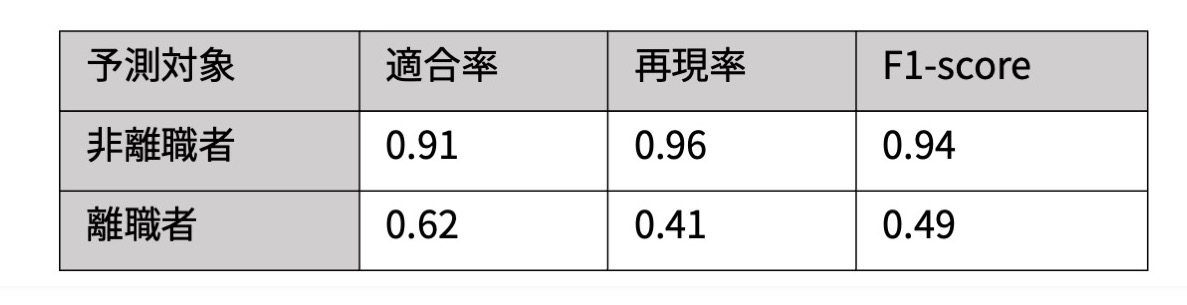
ランダムフォレストと同様に、非離職者に対する予測は良好に行われています。離職者に対する予測では、ランダムフォレストと比較して再現率が向上しており、F1-scoreが改善しています。ランダムフォレストに対して、非離職者を離職者と間違って予測する確率が増加していますが、離職者を見逃す確率は低下していると評価できます。
予測結果の価値
ここでは予測結果を適合率や再現率、F1-scoreで表していますが、これらの数字のビジネス上の価値は、この予測結果を何に使うのかによって変化し得ます。 例えば、離職予防を目指して離職ハイリスク従業員に対する事前対応を行いたいのであれば、離職者の再現率が非常に重要です。この時、離職者の適合率が低ければ、実際には離職しない従業員に対応する件数が増えることになり、コスト増につながります。 また、重要なプロジェクトに離職リスクの少ない従業員をアサインしたい、といった目的のためであれば、非離職者の適合率が最重要視されることもあり得ます。
考察・今後の検討事項
ここまでランダムフォレスト、サポートベクターマシンによる離職者予測を行った結果、非離職者に対する予測精度に対して、離職者の予測精度が低いことが分かりました。この結果をもとに、データ分析方法をさらにブラッシュアップする戦略を立てることができます。
データ数の不均衡の調整
まず、離職者の予測精度が相対的に低い原因として、データ数の偏りが考えられます。今回使用した1470例のデータの内訳は、非離職者が1233例と離職者が237例です。機械学習の過程で、非離職者のデータの影響が強く出過ぎている可能性があります。
この問題への対応には、おおまかに、①データ数のバランスをとる、②不均衡なデータに合った機械学習のアルゴリズムを採用する、という方針が考えられます。
①のデータ数のバランスをとる目的では、多い方のデータを削減する方法(Under-sampling)や、少ない方のデータを模擬的に生成することで水増しする方法(Over-sampling)、両者を組み合わせる方法(Combination- sampling)などがあります。
特徴量エンジニアリング
ここまでの分析では、元データに含まれる要素のうち、明らかに不要なものを除いた30種を分析に取り入れていました。この30種の要素がどれも等しく離職者の予想に意味をもつ、ということは考えにくく、無駄な要素が含まれている可能性があります。
反対に、これらの要素を使って新たな重要な要素を生成することもできるかもしれません。例えば、月収を時給で除して月間の実労働時間(割増給等は無視できるとして)を求めることや、実労働時間と職場と自宅の距離から、拘束時間やプライベートな時間の長さに関連する数値を生成できる可能性があります。(このデータセットの場合、月収と時給の値の定義が曖昧で、上述の計算を適切に実施できない可能性があります)
予測の役に立たないノイズを減らし、真に必要なシグナルを学習させることによって予測精度の向上が期待できます。
ニューラルネットワークなどの利用
今回は、比較的容易に導入できる機械学習アルゴリズムとして、ランダムフォレストとサポートベクターマシンを採用しました。当然ながら、機械学習アルゴリズムは他にも様々なものが開発されており、今回のデータや目的に合致して良い成績を出せるものが存在するかもしれません。
例えば、生物の神経ネットワークで起こる学習のメカニズムを模倣した「ニューラルネットワーク」という手法が広く活用されています。従業員が離職するかどうかは、おそらく、「AとBの条件を満たせば離職する」といった単純なルールではなく、多くの要素が絡み合った複雑な事象であると考えられます。そのような複雑な課題に対しても、ニューラルネットワークは高い精度で予測を実現できる可能性があります。
改善、改良を重ねていくデータ分析
今回は、AI、機械学習の手法を使って、人事データから離職者の予測を行う流れを紹介しました。基本的なアルゴリズムに手持ちのデータを投げ入れただけでは、満足できる予測精度が得られないことがあります。
実際のデータ分析でも、前回の記事や今回の記事で紹介したようなプロセスを繰り返していくことによって、ビジネス上有益な情報を引き出せるよう、改善、改良を重ねていくことになります。



