人事部門でのデータ活用:従業員の離職に関する分析~事前準備と基本的な分析~

データ分析は、収集されたデータから私達にとって重要で価値のある情報を引き出すための強力な手法です。収集されたデータの質や量が十分であればあるほど、より多くの有益な情報を引き出すことができる傾向がありますが、実際にそのような良いデータを入手することは簡単ではありません。手元にデータが揃わず、データ分析の価値を実感できていない方も多いのではないでしょうか?
ここでは、誰でも入手、利用可能なデータセットを使って、データ分析の大まかな雰囲気を体験できる記事を提供します。まずは、厳密さや精密さにはこだわらず、元のデータから情報を引き出していく流れの例をご紹介します
データ分析の概要
データ入手元
この記事では、データ分析に利用できる多くのデータセットが公開されている「kaggle」から入手したデータに対する分析例を紹介します。kaggle にはビジネス、気象や交通などの幅広いジャンルのデータが用意されています。
リンク先:kaggle Datasets
分析方法
Pythonを使用したデータ分析を行います。Pythonを使うと一般的な表計算ソフトでは難しい処理やAIなどへの展開が容易になります。
分析するデータ
従業員の離職原因について分析することを目的とした人事データを分析します。 データ(csvファイル)はこちらからダウンロードできます。
このデータセットは、IBMのデータサイエンティストが作成した架空のデータであり実在の人物に関わるデータや、ビジネス上の機密に該当するものではありません。実際に事業上収集されたデータを取り扱う場合には、セキュリティ対策や倫理的な配慮が必要となることにご注意ください。
例えば、この記事で紹介するような基本的な分析は、ChatGPTを使って簡単に行うことができます。しかし、ChatGPTに対して提示したデータのその後の取り扱いについては様々な懸念が存在するため、実際のデータを使うことは控えるべきです。
データ分析の流れ
1.データの理解
今回は、外部から入手したデータを使うため、まずはデータの理解が重要なステップとなります。データにどのような情報が、どのような形式で含まれているのかを確認することから始めましょう。
2.分析の目標設定
データを元に、どのような情報を引き出したいか、引き出せそうかを検討して分析の目標を設定します。
3.データの調整
データに欠損が存在する場合や、そのままでは扱いにくい形式になっている場合には、分析に適した形に変換する必要があります。また、分析の目標に対して関係がないデータ等があれば分析対象から外します。
4.データの分析
人事に関する一般的な知見や、データ内に現れている傾向を端緒に分析を進めます。さらに、統計的なアプローチを使って、目標達成に重要なデータを探索します。
5.分析結果に対する考察
得られた分析結果が何を意味しているのか、分析の目標は達成できているか、今後達成できそうかを検討します。
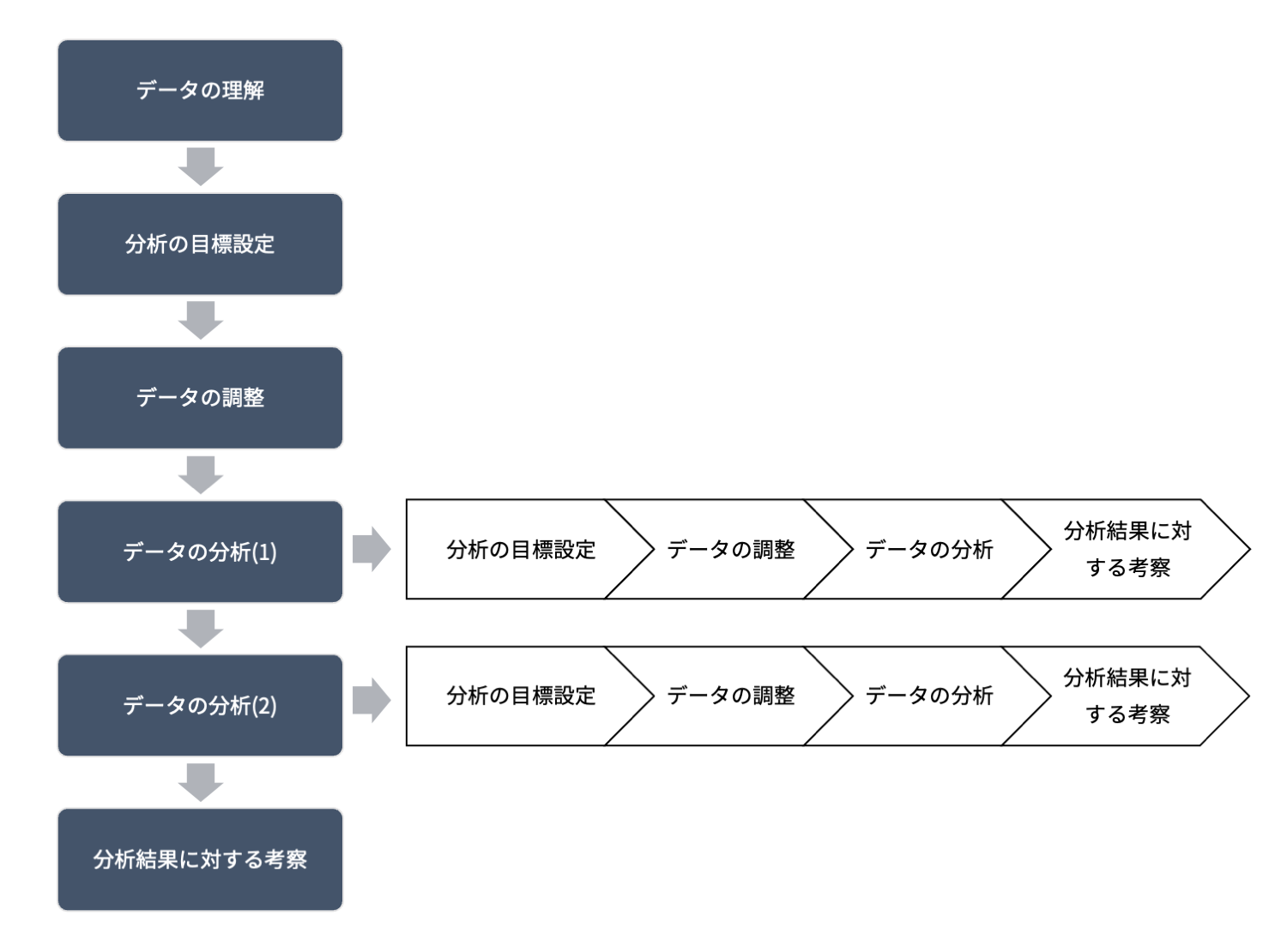
より詳細な流れとしては、分析は複数繰り返されます。データの分析(1)により、本格的な分析を始める前に必要な分析を行い、考察を行い、次の分析に何がするのか?を方向づけることができます。
実際のデータ分析
1.データの理解
ダウンロードしたcsvファイルを開くと、1行目にデータのラベルと思われる情報が入力されており、年齢やジェンダーのような基本的な情報や勤続年数や収入に関する合計35項目のデータが確認できます。行数を見ると1470件分のデータが含まれています。 この1470件には重複(各行の値が完全に一致する組)はありませんでした。また、データに欠損している部分は無く、分析しやすい状態になっています。
1 | Age | 年齢 |
2 | Attrition | 離職の有無 |
3 | BusinessTravel | 出張の頻度 |
4 | DailyRate | 日給レート |
5 | Department | 所属部署 |
6 | DistanceFromHome | 自宅ー職場間の距離 (マイル) |
7 | Education | 教育レベル(学歴) |
8 | EducationField | 学生時代の専門分野 |
9 | EmployeeCount | グループを構成する従業員の数 |
10 | EmployeeNumber | 従業員番号(各従業員に割り振られている?) |
11 | EnvironmentSatisfaction | 環境への満足度(4段階) |
12 | Gender | ジェンダー |
13 | HourlyRate | 時給レート |
14 | JobInvolvement | 仕事への関与のレベル(4段階) |
15 | JobLevel | 仕事のレベル(5段階) |
16 | JobRole | 仕事上の役割(職種、役職) |
17 | JobSatisfaction | 仕事への満足度(4段階) |
18 | MaritalStatus | 婚姻の状況 |
19 | MonthlyIncome | 月収 |
20 | MonthlyRate | 月収レート |
21 | NumCompaniesWorked | これまでに勤務した企業数 |
22 | Over18 | 18歳以上か? |
23 | OverTime | 残業の有無 |
24 | PercentSalaryHike | 昇給率 |
25 | PerformanceRating | パフォーマンスレート(4段階) |
26 | RelationshipSatisfaction | 人間関係への満足度(4段階) |
27 | StandardHours | 標準労働時間 |
28 | StockOptionLevel | ストックオプションレベル |
29 | TotalWorkingYears | トータルの勤続年数 |
30 | TrainingTimesLastYear | 過去1年間のトレーニング受講時間 |
31 | WorkLifeBalance | ワークライフバランス(従業員の実感、4段階) |
32 | YearsAtCompany | この会社での勤続年数 |
33 | YearsInCurrentRole | 現在の役職についてからの年数 |
34 | YearsSinceLastPromotion | 最後の昇進からの年数 |
35 | YearsWithCurrManager | 現在のマネージャーになってからの年数 |
データ形式に着目すると、年齢や収入などは数値で入力されていますが、ジェンダーや担当職務は文字列で入力されています。以降、異なる形式のデータが混在していることを前提に分析を進めていきます。
2.分析の目標設定
今回使うデータには「Attrition」という項目があり、解雇のような会社側の意図したものではない離職に関する情報が含まれています。そこで、今回は年齢、性別、収入などの情報を使って、離職する従業員と離職しない従業員の違いに関する分析を行います。
分析の具体的なゴールは様々に設定可能ですが、例えば、従業員の離職にとって重要な意味を持つ要素(離職を防ぐ意味で対応すべきポイント)の発見や、離職可能性の高い従業員の事前察知(予測)が考えられます。
3.データの調整
全ての情報が今回の分析目的のために有効であるとは限りません。不要な情報によって分析の精度が落ちる可能性もあるので、情報の取捨選択を行います。
Pythonの場合、各項目の最小、最大、平均などの値や標準偏差を簡単に調べることができるため、活用してみましょう。
全ての例で同じ値のデータ
まずは、データの中に一見して分析の対象にならないものがあれば、分析から除外します。ここでは、すべての例で同じ値を示すものを除外します。
9. EmployeeCount
22. Over18
27. StandardHours
の3つが該当します。
分析目的に合致しないデータ
10. EmployeeNumber
各従業員に割り振られたユニークな数字だと思われます。今回は個人を特定するような分析は行わないため、使用しません。
欠損値の処理
データに欠損している部分がある場合は、欠損値を平均値、最頻値などで補完する、欠損値がある例を削除するといった対応が考えられます。今回は欠損値が無いデータを使っているため。欠損値の処理は必要ありません。
4.データの分析
基本的な情報の確認
まず、1470例の内、離職者と非離職者の数を確認します。
件数 | |
離職者 | 237 |
非離職者 | 1233 |
合計 | 1470 |
このデータには離職者よりも多数の非離職者の情報が含まれています。
離職者vs非離職者 データ比較
従業員のどのような要素が離職率に関わるかについては、ある程度の多くの場面で共通する知見が広く知られています。例えば、年齢(若年者、入社後数年以内)や収入(あまりに低い賃金)、部署(特に労働負担が大きい部門やハラスメントの存在)などが想定されます。まずはこれらのポイントから、データを分析してみます。
まず、離職者と非離職者の年齢(Age)の分布を見てみましょう(Fig.1)。傾向として、離職者には若い従業員が多くなっていることが分かりますが、40代、50代になってもある程度の離職者が存在しています
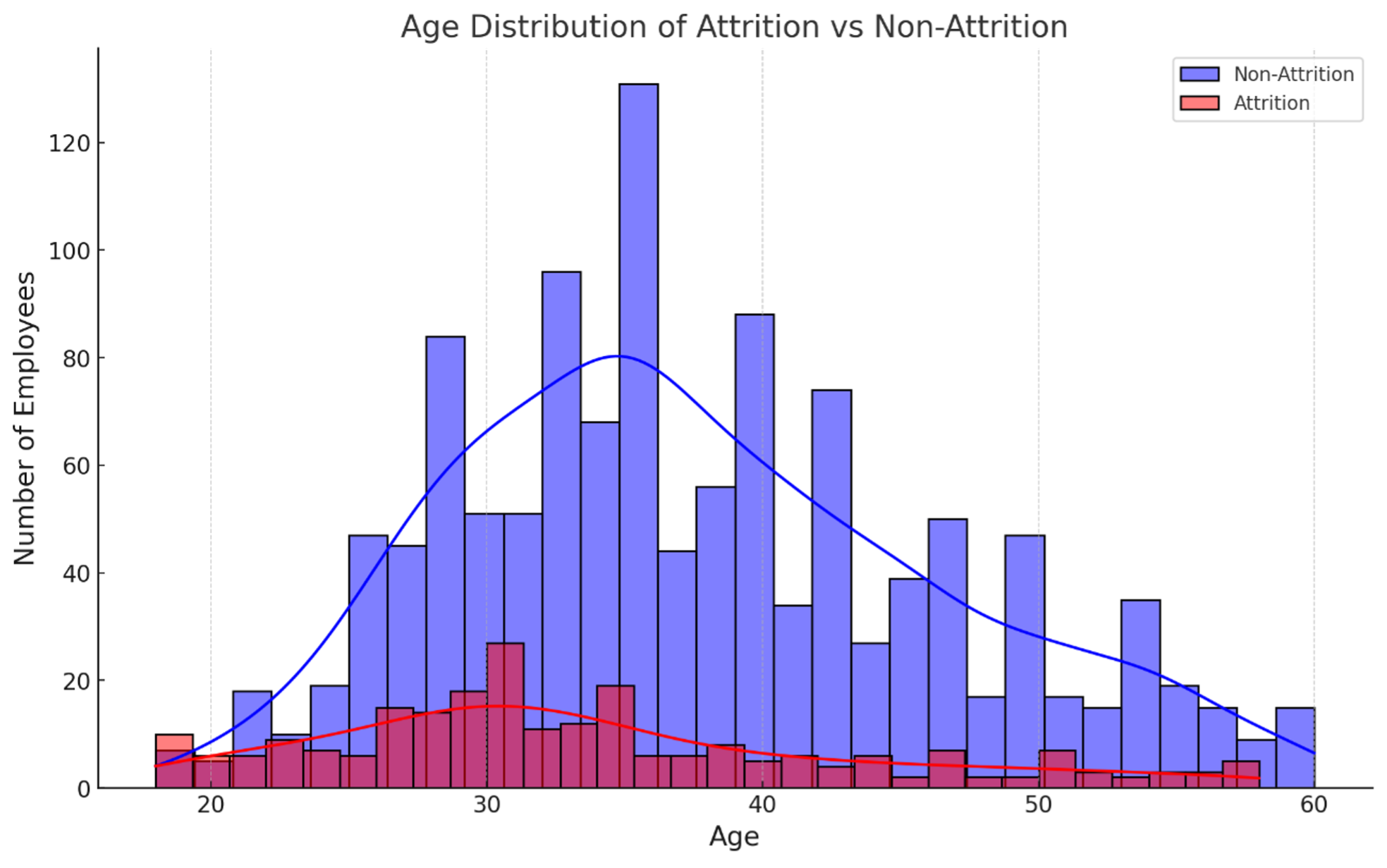
Fig.1 離職者と非離職者の年齢分布
次に収入について見てみましょう。この時収入が年齢(年齢と関連する勤続年数や役職を含む)と強く関連している点に注意しましょう。すでに離職者の方が若い傾向があることが分かっている以上、離職者の方が低い収入になる可能性が高いことも予想されます。
そこで、収入(MonthlyIncome)の値と勤続年数(YearsAtCompany)の値の2次元プロットを使って、離職者と非離職者の分布を確認します(Fig.2)。
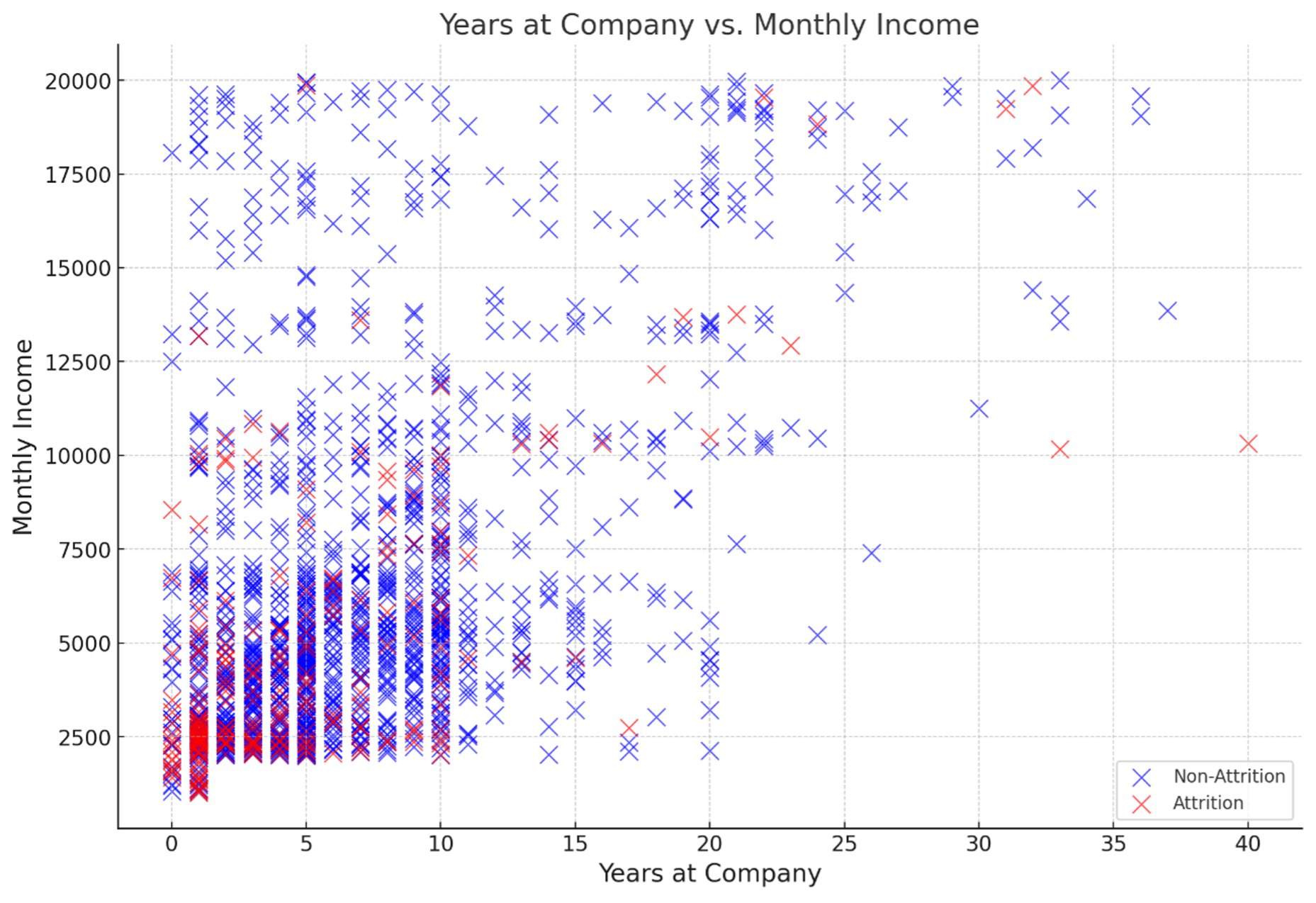
Fig.2 月収vs 勤続年数2次元プロット(離職者及び非離職者)
Fig.2では赤が離職者、青が非離職者を表しています。事前に予想したように、勤続年数が長いほど収入が高くなる傾向はあるようです。離職者が多いのは、勤続年数が短い層、月収が低い層であることが読み取れます。
次に、部署(Department)による違いを分析してみます。このデータには、Human Resources、Research & Development、Salesの3種の値が含まれていました。
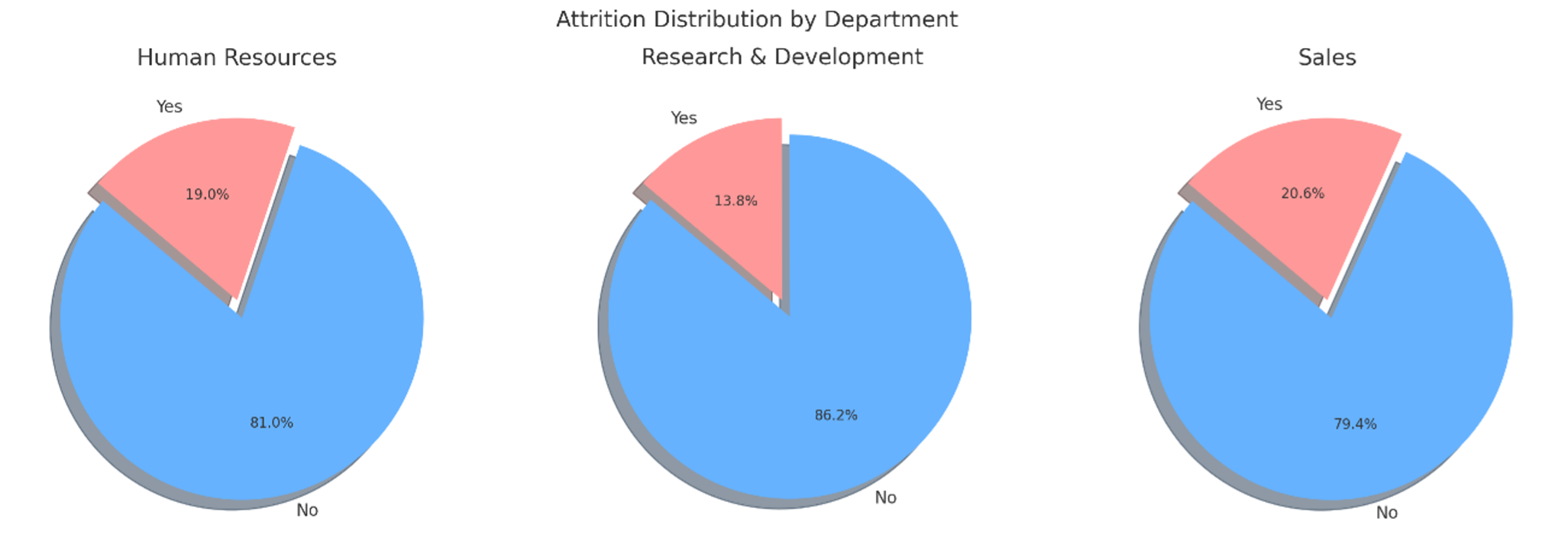
Fig.3 部署ごとの離職者と非離職者
この円グラフでは、離職「Attrition」の値がYesの場合は赤、Noの場合は青で表示しています。Human Resources、Salesに比べてResearch & DevelopmentにおけるYesの割合が少し低くなっています。
離職に関係する要素の探索
ここまでの分析は、おおよそ既存の知見を再確認するものではありますが、離職の予測における決定的な要素を見い出せていないことも事実です。今回のデータに含まれる項目の中に離職者の予想に効果を発揮するものが含まれているかを調べる方法はいろいろ考えられますが、ここでは相関係数を利用してみます。
例えば、離職を1、非離職を0と置き換えると、数値で表される他の要素との相関係数を求めることができます。相関係数は、必ずしも因果関係を表すものではありませんが、離職と関係する要素を探索する目的としては効果的な方法になり得ます。
要素 | 相関係数 |
DistanceFromHome | 0.078 |
NumCompaniesWorked | 0.043 |
MonthlyRate | 0.015 |
PerformanceRating | 0.003 |
HourlyRate | -0.007 |
PercentSalaryHike | -0.013 |
Education | -0.031 |
YearsSinceLastPromotion | -0.033 |
RelationshipSatisfaction | -0.046 |
DailyRate | -0.057 |
TrainingTimesLastYear | -0.059 |
WorkLifeBalance | -0.064 |
EnvironmentSatisfaction | -0.103 |
JobSatisfaction | -0.103 |
JobInvolvement | -0.130 |
YearsAtCompany | -0.134 |
StockOptionLevel | -0.137 |
YearsWithCurrManager | -0.156 |
Age | -0.159 |
MonthlyIncome | -0.160 |
YearsInCurrentRole | -0.161 |
JobLevel | -0.169 |
TotalWorkingYears | -0.171 |
数値で表される要素の相関係数を調べてみると、全ての要素で0.1~-0.2の範囲に収まっており、各要素単体と離職の間にはほとんど相関は見られないことがわかります。 ここでは、要素の中で有望なものを探すことが目的ですので、非常に弱い相関の中でも数値を比較してみます。TotalWorkingYears(これまでに他社を含む会社に在籍したトータルの年数)が-0.171で最も強い相関がみられました。これは、「会社に在籍していたトータルの年数が長い人ほど離職しにくい」という負の相関を表しています。もう少し表を見てみると、相関係数が-0.1を下回る要素は、年齢と強く関係するような時間的なパラメーターがほとんどです。
5.データ分析結果に対する考察
ここまでの分析によって、離職に関わる要素として年齢や勤続年数、それらに伴って増加する収入など、時間的要素を含むパラメーターが挙げられました。しかし、各要素と離職の有無の間の相関は非常に限定的であり、それらの要素単体で当該従業員が離職するかどうかを予測することはできそうにありません。今後は、複数の要素を踏まえた条件判断式の構築や、各要素を組み合わせて新たなパラメーターを作り出すことが有効な手段として想定されます。
時間的な要素が重要であると見込まれる場合、データや分析結果の解釈にあたって、データの取得経緯を考慮に入れる必要があります。例えば、過去10年の離職者データと、今年の在籍従業員データがまとめられているような場合、そもそもデータの取得段階で時間的な歪みが含まれる可能性が考えられます。
今後の展開
おそらく、このデータから離職を精度よく予測するためには、複数の要素を総合的に判断する基準を作る必要があります。30を超える要素を組み合わせるパターンは無数に存在するため、人力での探索は効率的ではありません。そのような場合は、いわゆるAIと呼ばれるような手法によって、効果的な判断方法を創出してみることが良さそうです。「事部門でのデータ活用:従業員の離職に関する分析~AI、機械学習による分析~」では、同じデータを使ってAIによる離職者予想方法をご紹介します。




