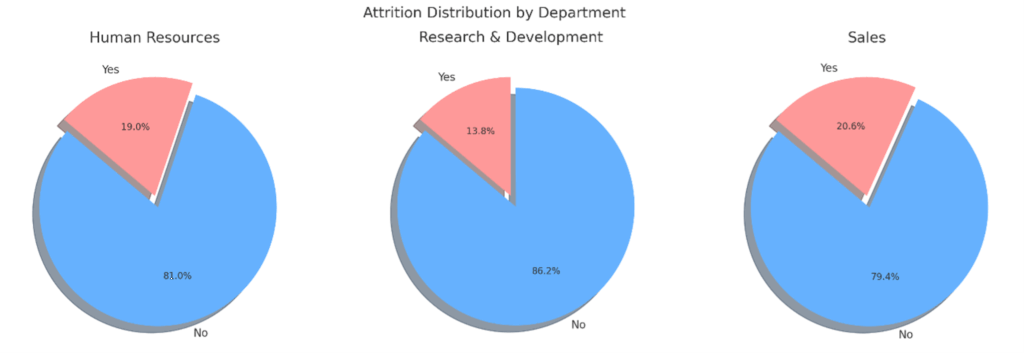
マーケティングの役割を180度変えた「ブランド資産」という概念
ブランドとは何ですか?と聞かれて、躊躇せずに答えられるマーケターは実はそんな多くないように思います。
実務では、レギュレーションが用意されていて、ロゴの使い方や色、フォントまで定められているので、レギュレーションに従って制作物の確認作業を行います。ブランド統一に関しては、ある程度の規模のある企業では、役員や上司、もしくはデザイン会社クリエイティブディレクターから厳しくチェックされます。このような作業を行うことで、ブランドイメージの統一をはかることはもちろん大切なことですが、そもそもブランドとは何なのでしょうか。
ブランドに対しての概念は、1980年代後半に大きく変わり、ブランド・マネジメントの役割も変化していきました。そして、デジタル化、グローバル化の波を受けて、ブランド・マネジメントを行うマーケティングの業務はより高度化しています。
それではブランドとは何か、ブランド・マネジメントとは何か、企業において中長期的なブランド育成が根付かない理由は何か、考えていきましょう。
ブランドとは何か
ブランドとは、企業や商品・サービスが持つ独自の「らしさ」、ユーザーが抱く共通のイメージです。他社と区別するための要素でもあります。
しかし、ブランドという概念が注目され、ブランドの持つ無形の価値が評価されたのは、最近のことです。デービット・アーカーによって「ブランドとは資産である」と提唱され、1980年後半にアメリカで登場した比較的新しい概念です。つまり、「ブランドとは資産である」――ブランドが企業の事業戦略や業績に関わるという考えです。
ブランドが資産という概念が生まれた背景
1980年代の初頭にPOSシステムの導入が進み、リアルタイムにデータを確認することができるようになり、様々な実験が可能になりました。様々な実験とは、例えば、20%OFF、タイムセール、まとめ買いでお得などのディスカウントです。
今ではマーケティングは中長期の視点を持って活動すべきというのは広く知れ渡っている認識です。しかし、このPOSシステムの普及とリアルタイム・データの台頭で、マーケティングは短期的な戦術を連発することになり、価格が購入決定要因になりました。短期的な戦術を連発したブランドは、ブランドによる差別化を図ることもできない状態となり、ブランド・エクイティとロイヤリティーを回復することに時間をかけることになりました。
さらに、企業は売上増加のためのコスト削減のインパクトも限度が知れていたので、新ブランドに開発やブランドの拡張を模索していました。当時、新ブランドの立ち上げをするにも、拡張するにも、ブランドを資産として活用していくブランド戦略を必要としていました。
また、定量的なデータでも、ブランドが資産価値を持つということが示され始めた時期でもありました。そうしたタイミングが重なり、ブランドを資産とした見方を採り入れる企業が少しずつ増えていきました。
ブランド構築の目標はブランド・エクイティを高めること
ブランド・エクイティ(Brand Equity)という言葉を、マーケティングやブランディングに関わった人が一度は耳にしたこともあるのではないでしょうか。エクイティ(Equity)は、株式や自己資本という意味をします。つまり、ブランド・エクイティはブランドが持つ資産、ブランド資産という意味で、「ブランドの名前やシンボルと結びついた資産(負債も含む)の集合」と考えられています。ブランド・エクイティの向上よって、製品やサービスの価値や魅力は増大させることができます。
ブランド・エクイティを築き、向上し、活用するためには、ブランド認知、ブランド連想、ブランドロイヤルティの主な3つの構成要素を育てる必要があります。
- ブランド認知
- ブランド連想
- ブランドロイヤルティ
- 知覚品質
- その他ブランド資産
さらに、D.A.アーカーによると、知覚品質、その他ブランド資産を含めて、5つがブランド・エクイティの構成要素と提唱され、多く企業でモデルとして役に立つものでしょう。
ブランド認知に関して
ブランド認知に関しては、認知度とよく表現されているのではないでしょうか。認知度や想起率が高いほど、顧客の購入プロセスの決定的な場面でブランドを思い出してもらえる可能性が高くなります。
- ブランド認知度とは
ブランド認知度は、100人に「FLOURISHって知っていますか?」と質問したとします。その時「知っている」と答えた人が、100人中90人いたとします。この場合のブランド認知度は、90%という事になります。
- 想起率とは
最初に想起されるブランドをトップ・オブ・マインドと言われています。例えば、「大学受験の予備校は?」という質問をされたら、みなさんはどのようなブランド(予備校や学習塾)を思い浮かべますか?
商品・製品のカテゴリーを聞いて思い出すか、これを純粋想起(ブランド再生)といいます。純粋想起率が低いと購入の際の選択肢に入ってこないので、想起率を上げることは重要です。
さらに、特定のブランドの名前やロゴ、画像を見て思い出すことを助成想起(ブランド再認)と言います。助成想起率が高いと、購買の動機につながりやすい状態と考えられています。
ブランド連想に関して
ブランド連想とは、そのブランドを連想させるもの。
例えば、Tiffany & Coといえば、青い箱を連想するのではないでしょうか。
これがブランド連想です。古くから青は、真実や高潔さのシンボルでもあり、「ティファニーの品々はどれも気高くあらねばならない」という信念を表すものになっています。
どのような連想を持たせたいのかを決め、その連想を強化するような計画を練り、実施していくことで、その連想とブランドを結びつけます。ブランドを資産としてマネジメントする際にとても重要なことです。
ブランドロイヤリティーに関して
ロイヤリティは英語ではLoyaltyと書き、Loyaltyは忠実、忠誠の意で、会社、ショップなどに対する顧客から店に対する親密性や信頼性を指します。
顧客のロイヤルティ(顧客が特定の企業やブランドのサービス・商品に対して持つ信頼や愛着心)で、ブランドロイヤリティは成り立っています。
高いロイヤリティーを持つ顧客は売上に貢献し、新規顧客を獲得することよりも、既存顧客のリピートを作り、維持する方が費用や労力が安くすむ場合も多いでしょう。「20%の優良な顧客が企業の売上全体の80%を担う」というパレートの法則があります。
このブランドロイヤリティーを高めることで、「他のブランドを試してみたい」という気持ちを無くします。比較検討を必要とせずに、「そのブランドを購入したい」という顧客の気持ちを高めることができ、リピートや顧客単価の向上に繋がり、安定した売上の確保につながります。
ブランドロイヤリティは「Net Promoter Score(ネット・プロモーター・スコア:NPS®)」という指標を用いて計測するのが一般的です。
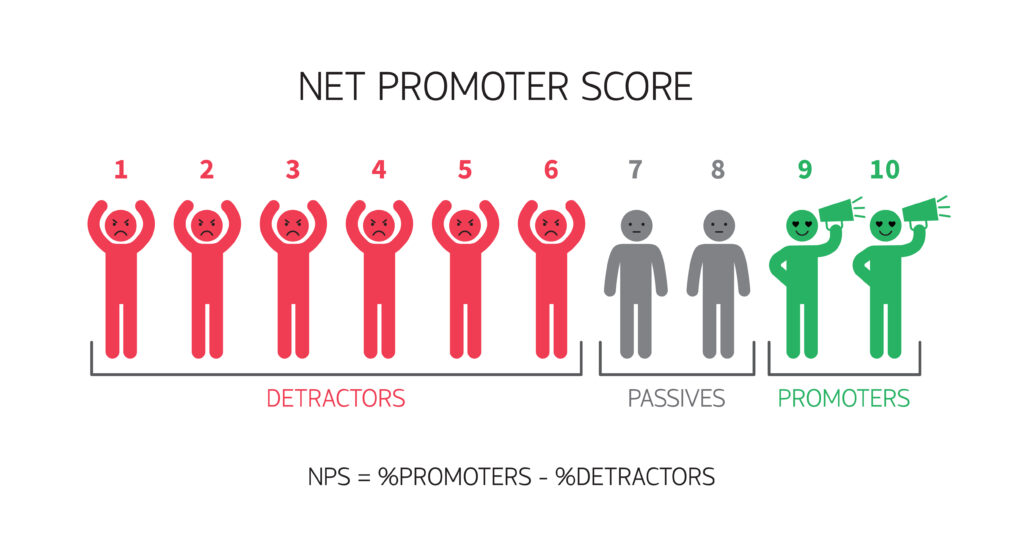
該当する商品やサービスを周囲に勧めたいかどうかの評価をアンケートで調査します。
知覚品質に関して
知覚品質が改善すればROIも向上すると考えられています。顧客が感じているブランドイメージ、品質のことを指します。品質だけでなく、信頼性や雰囲気といった側面も、知覚品質に含まれるものとされています。
その他のブランド資産に関して
特許のような資産など所有権のある他の資産が含まれています。
ブランドが資産という見方をするとマーケティングの役割も変わる
短期的な売上を上げるような戦術的な評価基準から、ブランド・エクイティを向上させるような戦略的な評価基準へと重点を変化させることは大きな変化であり、挑戦になります。
評価基準の重点を変化させることで、マーケティングの役割も変わります。それまではマーケティングの役割が販売促進であると考えられていました。マーケティング・マネージャーは、広告宣伝の出稿、広報やプロモーションの計画を立案し、スケジュールの進行管理をしていて、戦術を実施する業務を回すタスクマンです。
しかし、ブランド・エクイティの向上に重点が置かれると、マーケティングの業務は戦術的で受け身の立場から戦略的でビジョンを描く立場に変わっていきました。(つまり、ブランド・ビジョンのない会社では、マーケティングは残念ながらタスクマンとなってしまうという現象は致し方ないことです。)
今日ではデジタル化が進み、集客チャネル(集客する媒体・経路)も増え、コミュニケーションのあり方が複雑になりました。例えば、下記のようなチャネルが存在します。
コミュニケーション・チャネル
- ウェブサイト
- ソーシャルメディア
- パンフレット
- チラシ、ポスター
- テレビ、ラジオ
- 屋外広告
- DM
- 新聞、雑誌広告
- オンライン広告
- イベント
これに加えて、流通チャネル、販売チャネルも。販売チャネルには、店舗やECサイトなどが当たります。マーケティングがブランド・マネジメントに関わる範囲としては、販売チャネルとコミュニケーション・チャネルになります。
販売チャネルと複数のコミュニケーション・チャネルを統合的に管理し、統一されたメッセージの発信を企業はしく必要があります。コミュニケーション・チャネルを総合的に管理する戦略は、IMC(Integrated Marketing Communication)と言われ、日本語では総合型マーケティング・コミュニケーションと呼ばれています。
経営層と話し合いを重ねてブランド・ビジョンを策定し、明確なブランド・ビジョンに従って、ブランド資産を構築していく。どんな風にブランドを連想してもらいたいか考え、ブランド連想を強化する計画を練り…、複数のチャネルを管理する。売上増大というシンプルな課題よりも難しいことです。
さらにグローバル展開するようなサービスであれば、製品の数が増え、提供する国が増えていけば、管理することが増えていくでしょう。
今日でもブランド資産という概念が浸透しない理由は
「ブランドは資産である」だから、中長期的な戦略として重要な指標として扱いましょうというスタンスに企業はなかなか切り替えられないでいる現状は今日でもあります。
特に、BtoB企業やハイテク業界、製造と販売に注力している企業では、今もなお、ブランド戦略は受け入れにくいのが現状ではないでしょうか。
それには、短期的な財務業績の力が圧倒的に強く、経営者からも短期的な数字が満足感を得られやすくなっていることが一つ理由としては挙げられるでしょう。企業は株式の利益の最大化を目指しているため、株の利益に影響を与える短期的な収益を優先します。そのため、短期的な業績を改善した人を評価し、昇進させやすいシステムになっていて、評価される側も短期的な改善を優先して取り組んでしまう傾向があります。前述のように、短期的な戦術だけを繰り返していくことで、ブランド資産が損なわれた歴史もあるので、短期的な戦術と中長期的な戦略の比重でバランスをとることはとても大事なことです。
さらにブランド戦略などの無形な資産を重視していないカルチャーでは、マーケティングと営業の力関係で言えば圧倒的に営業が強くなりがちとも言えるでしょう。営業の力が強くなるほど、明日にでもできる短期的な戦術を重視します。その結果、ブランド資産だけでなく、優秀なマーケターの疲弊と離脱が起きやすくなります。
短期的な施策に対して手を動かせる優秀なマーケターもまた限られていて、優秀でやる気のある中堅から若手のマーケターに仕事は偏り、疲弊するという構造は多くの企業で見られることです。
中長期的な戦略を考えること、短期的な戦術を実施することのバランスをみることから始めてみるとよいのかもしれません。