増える分析ニーズとともに進化するデータ分析基盤:データレイク・データウェアハウス・データマート
データ分析のインフラ設計やデータ基盤の構築は、データ活用のステップのどこ?
データ活用というと視覚化の部分のみがフォーカスされることがあります。しかし、データ活用は、データの前処理やデータ基盤構築も重要な役割を果たしています。
データ活用のステップは、下記のような流れが一般的と言われています。
データの探索と準備
課題の把握
データの特徴の把握
目的の把握
目的、設定、評価基準、入力、出力
分析
考察
データの変換・データインフラの構築
データの視覚化とプレゼンテーション(レポート・BI)
データモデリング(モデル構築・予測)
意思決定
データ基盤の構築は「2.データの変換・データワークフローの構築」の部分であり、分析を支える重要な役割をします。
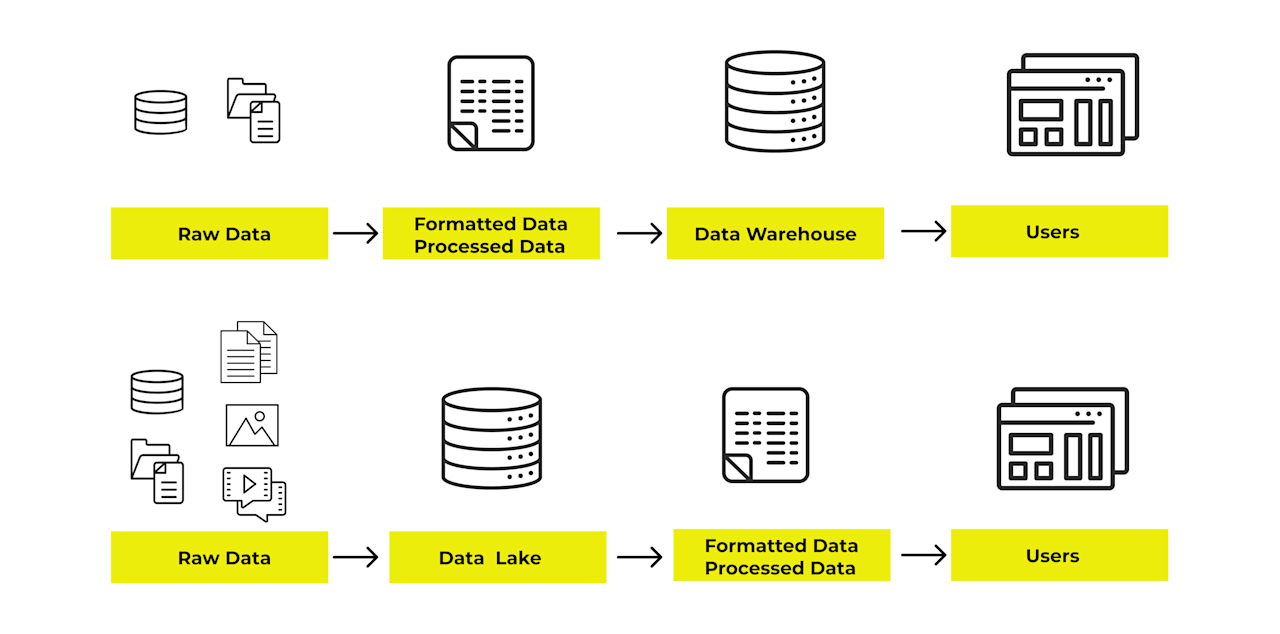
データ活用に関しては、大きく分けて2つのパートでシステムは構成されていると考えられます。
データを貯めるところ
データを分析するところ
データ分析をするところは、非エンジニアでもBIツール(例:Google データポータル、Microsoft Power BI、Tableau)が思い浮かぶと思います。 では、データ分析に活用するデータを貯めるところは、どこでしょうか?
データウェアハウス(DWH)やデータレイク、データマートなどがデータ分析に活用するデータを貯めるところにあたります。
データウェアハウスの概念は、1990年に誕生したと言われています。
分析作業にはリソースを大量に使うことから、業務を実行するITシステムから分離し、リソースの制約なしに分析作業ができるようにする必要があります。
つまり、大量のデータを分析しようとするとデータを貯めるところは必須であり、データ分析およびデータ戦略をサポートすることに重要な役割を果たします。そして、人々は、データはアクセス可能な場所に保存され、適切にクリーンアップされ、定期的に更新される状態を望むでしょう。
今回は、増え続ける分析ニーズに応えるために進化したさまざまなデータアーキテクチャ(ビジネスで取り扱うデータを設計するための考え方、あるいは設計)について、データプラットフォームを中心に紹介します。
データプラットフォームの代表的なコンポーネント
データプラットフォームのアーキテクチャにおける代表的なコンポーネントとして「データレイク」、「データウェアハウス」、「データマート」があります。
データレイクとデータウェアハウスは比較されていますが、相互に補完することができます。「データレイク」、「データウェアハウス」、「データマート」それぞれの特徴について紹介します。
データレイク
さまざまなソースから収集したデータを、一元管理で貯めておけるリポジトリ(貯蔵庫、収納庫)のことです。「構造化データ」「半構造化」、音声、画像、ビデオなどの「非構造化データ」など、あらゆるサイズ、タイプ、形式のデータに対応できるストレージ システムです。
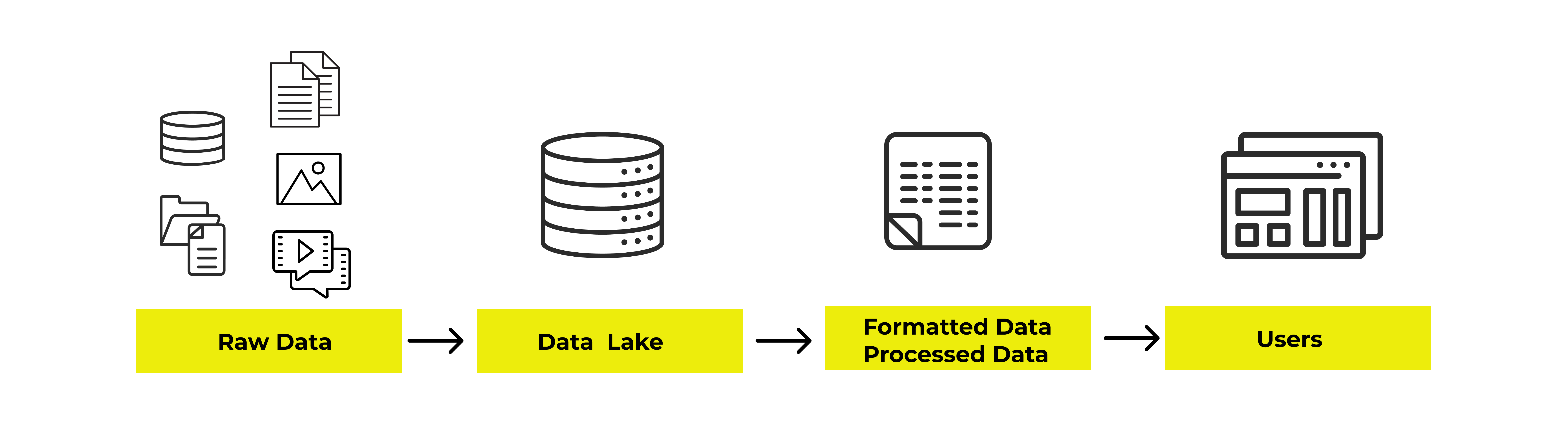
主な製品:AWS Data Lake / Google Data Lake / Azure Data Lake / Snowflake Cloud Data Platform / Cloudera Data Platform etc
データウェアハウス
製品によって異なりますが、構造化および半構造化 (JSON、XML)を扱うことができます。データウェアハウスによっては非構造化データを扱うこともできます。事前定義された目的に合わせて処理をしたデータを保存します。
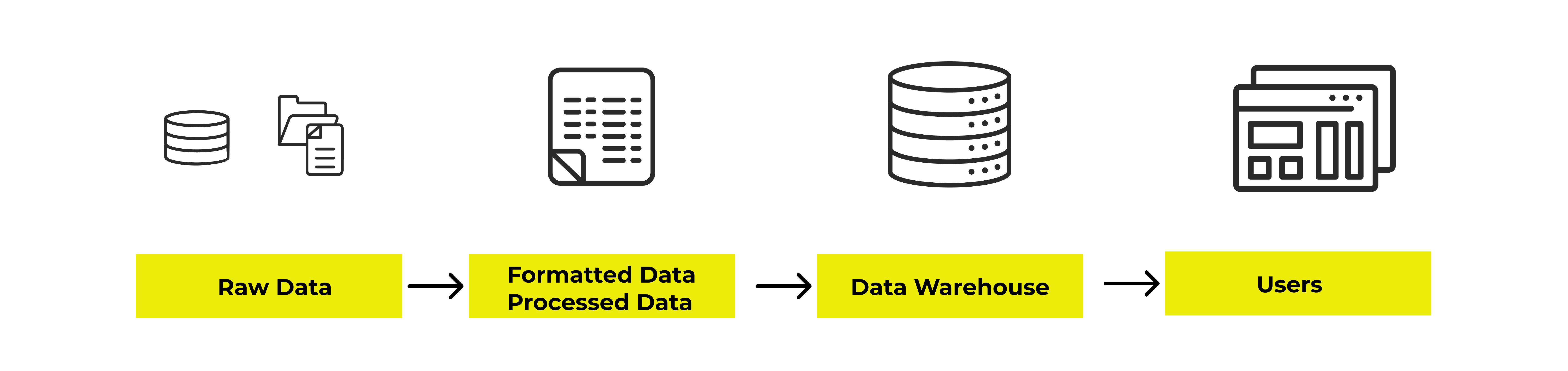
主な製品:Amazon Redshift / Amazon Athena / Google BigQuery / Azure Synapse / Snowflake etc
データマート
データ マートはデータ ウェアハウスと非常によく似ています。組織内の特定の部門、部門で使用できるように設計されます。
基本的に、データ マートはデータウェアハウスのデータをサブジェクト(主題)ごとに分解、整理します。データウェアハウスのサブジェクト指向です。
または、生データ(Raw Data)をデータ分析に活用できる構造化データに変換します。ETL プロセス(抽出、変換、格納)[※]などを活用して、生データのクレンジングや変換を行なった上で、データをデータマートに取り込みます。
下記はデータマートの種類です。
従属型:既存のデータウェアハウス( DWH )からデータを抽出または加工し作成されるデータマート
独立型:データウェアハウス( DWH )とは別のソースからデータを得て加工されるデータマート
ハイブリッド型:複数のソースからデータを抽出または加工して作成されるデータマート
※ ETLプロセスとETLプロセス
ETLプロセスは「Extract (抽出)」「Transform (変換)」「Load (格納:書き出し)」の略語です。 データベースやシステムからデータを抽出し、扱いやすいフォーマットに変換して、DWH(データウェアハウス)に書き出す一連のプロセスです。
一方で、ELTのプロセスは「Extract (抽出)」「Load (格納:書き出し)」「Transform (変換)」を表します。ELTプロセスは、生データ(Raw Data)をシステムからデータウェアハウスなどの出力先にデータを移動するプロセスで使われます。データ基盤がオンプレミスからクラウド環境への移行に伴い、ごく最近に採用されるようになったものです。
データレイクとデータウェアハウスとデータマートの比較のまとめ
データレイクには、1つ以上のシステムからの履歴データがそのままの形式で保存されます。構造化データだけでなく、音声や画像や動画などの非構造化データや、半構造化データも保存することができます。データレイクはELTプロセス(抽出、格納、変換)であることが多いです。
データウェアハウスは、 1 つ以上のシステムから履歴データを事前定義された構造化データにして保存されます。データウェアハウスはETLプロセス(抽出、変換、格納)であることが多いです。
多くの場合、利用可能なリソースとニーズ(目的、使途)によってETLとELTのどちらを選択するかを選択するかによります。

データレイクとデータウェアハウスとデータマートを組み合わせた活用メリット
3 つのコンポーネントは、次のような 3 つの異なる機能を担当し、相互に保管しあえます。にデータ レイクに保存されている生データが必要な場合、そのデータを抽出、クリーニング、変換し、データ ウェアハウスで使用してさらなる分析を行うことができます。
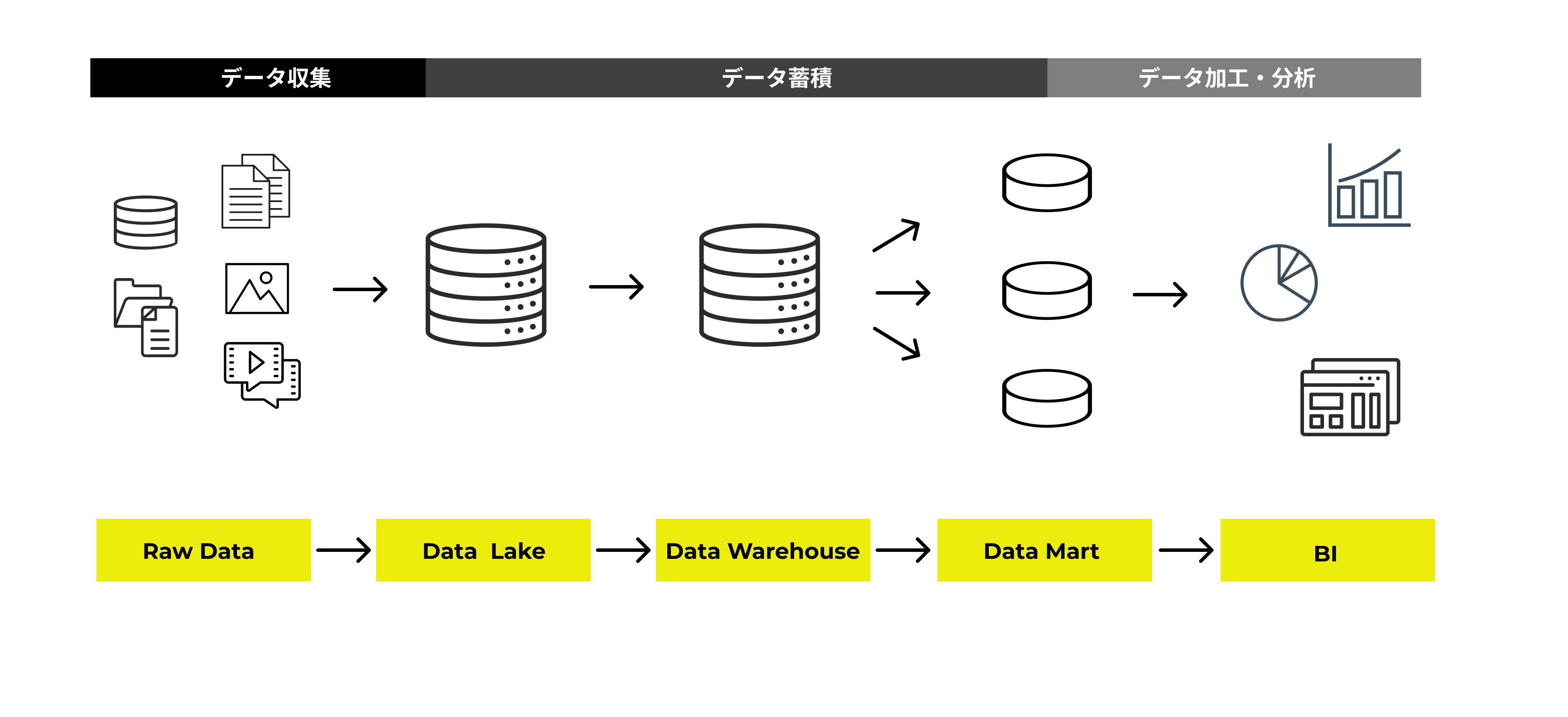
データは、バッチ処理 (一定間隔での読み込み) とストリーミング の 2 つの方法で読み込みます。生データ(Raw Data)を受信し、後で使用できるように準備するために使用される複数ステップのプロセスは、ELT (抽出、格納、変換) と略されます。
データプラットフォームのアーキテクチャー設計:ユースケース
データレイクとデータウェアハウスとデータマートを組み合わせ、どのようなツールを使って、データワークフロー(データ分析作業)を行なっているのでしょうか。下記は一例になります。
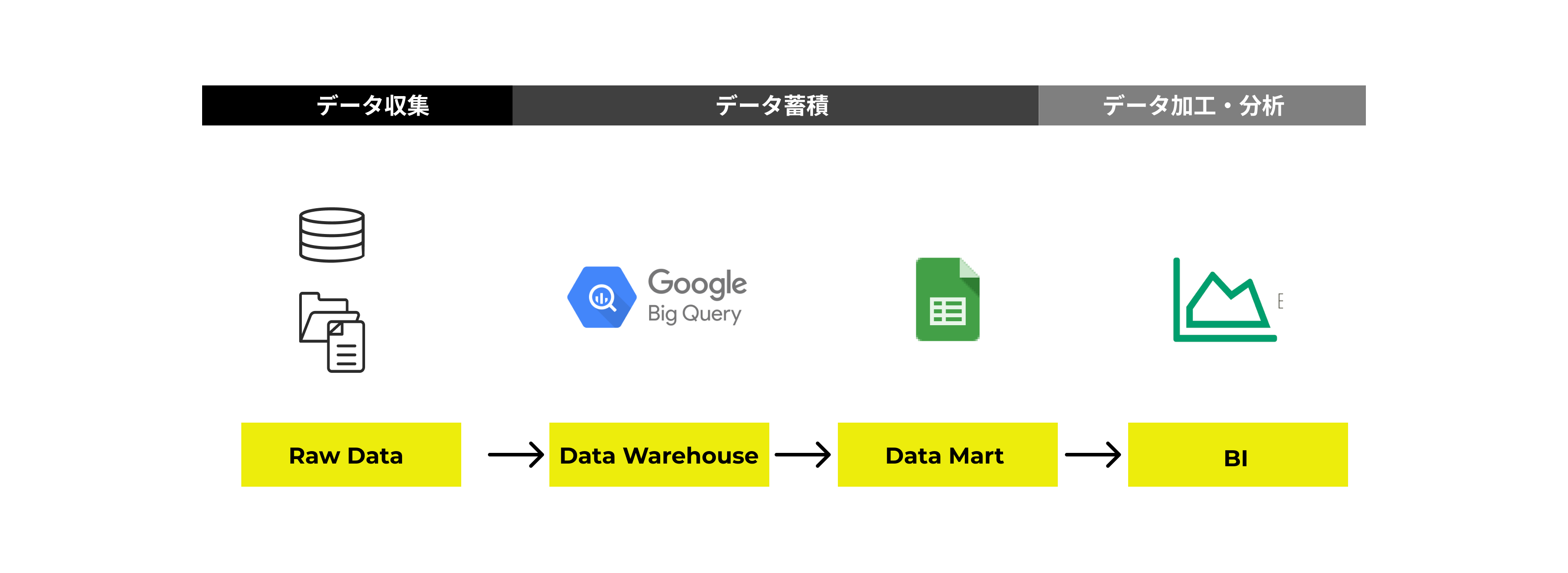
次回の記事では、上記のデータアーキテクチャーのユースケースを実践したいと思います。データ ウェアハウスとして Google BigQuery にデータを保存し、データ マートにGoogle スプレッドシートを使用します。BIツールには、Exploratoryを活用し、レポーティングします。





