データ分析の前段階「データ探索」の重要性と手法:顧客データで実践解説
データサイエンスによるデータ活用のステップは、下記のような流れが一般的と言われています。
データの探索と準備
課題の把握
データの特徴の把握
目的の把握
目的、設定、評価基準、入力、出力
分析
考察
データの変換・データワークフローの構築
データの視覚化とプレゼンテーション(レポート・BI)
データモデリング(モデル構築・予測)
意思決定
多くの場合は、「1.データの探索と準備」だけで考察をして終わってしまったり、取り急ぎ「3.データの視覚化とプレゼンテーション(レポート・BI)」のみを簡易に済ませてしまったりすることが多いのではないでしょうか。「1.データの探索と準備」に関しては、データサイエンスに知見がある人が考察までを行うような範囲で留まってしまうこと、3に関してはBIツールにデータを入れてとりあえず視覚化できるようにした状態のことです。
1〜5のステップを行うことで、適切に高度にデータを活用できる状態になります。特にデータ活用に関連する作業において、1~2の占める割合は90% 以上とも言われていて、とても重要なステップです。
今回は、最も重要なプロセスでもある「1.データの探索と準備」はなぜ重要なのか、考えてみましょう。 後半で、初級者向きのKaggleのデータセットを使い、データの探索の入門「支出スコアと年収の関係は?」と題して、データの探索の重要性を紹介しています。(完全なコードはGithubにあります。)
Exploratory Data Analysis(EDA:データの探索)とは何か?
ビジネス課題を解決するために、データセットに変更を加えたり、モデルを構築したりする前に、最初に行われる作業です。
データセットを分析および調査するため、データの特徴を要約したり、データを視覚化したりする方法が取られます。
モデリングや仮説テストでデータが何を明らかにできるかを確認するために使用され、データセットの変数とそれらの間の関係をより深く理解できるようにします。
Exploratory Data Analysis(EDA:データの探索)はなぜ重要なのか?
データサイエンスやAIによるデータ活用において最初に直面する課題は、データが特定の問題にどのように価値をもたらすことができるかを判断することです。 EDA(データの探索)により、データがモデル構築と仮説テストで何を明らかにできるか確認することができ、最終的には望ましいビジネスの成果や目標に適用できるかを決定づける作業とも言えるでしょう。
EDAの手順は下記のような流れになります。
データ収集
データセットを把握
データセットのクリーニング
適切な統計手法の選択
結果の視覚化と分析
EDA では、手元にあるデータを汚す前に、そのデータを理解することができます。 変数とデータセットの構造を理解することが、このプロセスの最初の段階です。
値の欠落やデータの重複にすでにイライラしますよね。お掃除が必要です。 データの前処理とクレンジングは、EDA の重要なコンポーネントです。 この段階で、何をクリーニングする必要があるか、またそのクリーニングをどのように実行できるかを決定します。これはデータ前処理と呼ばれます。明らかなエラーを特定するだけでなく、データ内のパターンをより深く理解し、外れ値や異常なイベントを検出し、変数間の興味深い関係を見つけるのにも役立ちます。
さらに、データサイエンスの流れの「2データ表現と変換」⇄「3データ分析を実装」では、データレイクやデータウェアハウスを利用して、適した形式に整形してデータを集める仕組みを作るか、集まったデータを分析できる形に変換する仕組みを作るかを、EDAを行うことにより具体的に検討することができます。
EDA(データの探索)の副次的な目的
EDA(データの探索)の目的は、データがモデル構築と仮説テストで何を明らかにできるか確認することですが、副次的な目的があることがわかります。
下記は主な副次的な目的になります。
データの外れ値の特定と削除
時間や空間による傾向を特定する
パターンを明らかにする
仮説を立てて実験で検証する
新しいデータソースの特定
EDA(データの探索的な分析)は、とても欠かせない作業であることがわかります。
Exploratory Data Analysis(EDA:データの探索的な分析)の種類
EDA は、最終的に概要や視覚化する必要があり、それには主に 4 つのタイプがあります。
単変量解析・非グラフィカル(Univariate Non-graphical)
平均値、中央値、最頻値、分散、標準偏差など
単変量解析・グラフィックス(Univariate graphical)
ヒストグラム、箱ひげ図、QQプロット
多変量解析・非グラフィック(Multivariate Non-graphical)
3 つ以上の変数の表作成、クロス集計、分散分析など
多変量解析・グラフィックス(Multivariate graphical)
散布図、ヒートマップ、折れ線、多変量チャート、バブル チャート
Exploratory Data Analysis(EDA:データの探索)の分析ツール
Python、R、Excel は、人気のある EDA ツールの一部です。
Python: データの欠損値の検索、データの説明、外れ値の処理、グラフの作成のための関数が多数あります。自動化し、時間を節約できるオープンソースもあります。
R: はオープンソースのプログラミング言語でもあり、統計学者やデータ サイエンティストによって分析に広く使用されています。Python と同様に、R も統計計算やグラフィックスに適したオープンソース プログラミング言語です。
Excel :Excel は、データ探索を開始するための最も簡単なツールです。アドオンを使うことができます。
EDA:データの探索の入門「支出スコアと年収の関係は?」
データの探索と準備に関して概要を説明してきましたが、実際にどのようなことがデータ探求なのか、データの探求をなぜ行わなければいけないのかを体感していただけるように、簡単な事例を用意しました。
使用したデータセットは、性別、年齢、年収、支出スコア(0 ~ 100 の範囲)に関する顧客データです。
目的としては、支出習慣の傾向を知って、予測から何らかのプロモーション施策を打つことができないかということを考えていたとしましょう。
何となく、「年収が増えれば支出スコアも上がるでしょ?」「年収自体が男女で差があるんじゃないか?」と思いませんか。(こういった先入観でプロモーションすることは、実はよくあるのかもしれません。)
予想としては年収と支出スコアの相関が取れるのではないだろうかと当たりをつけて、データ探求を始めることとします。
まず、データに関して基本的な情報を把握してみます
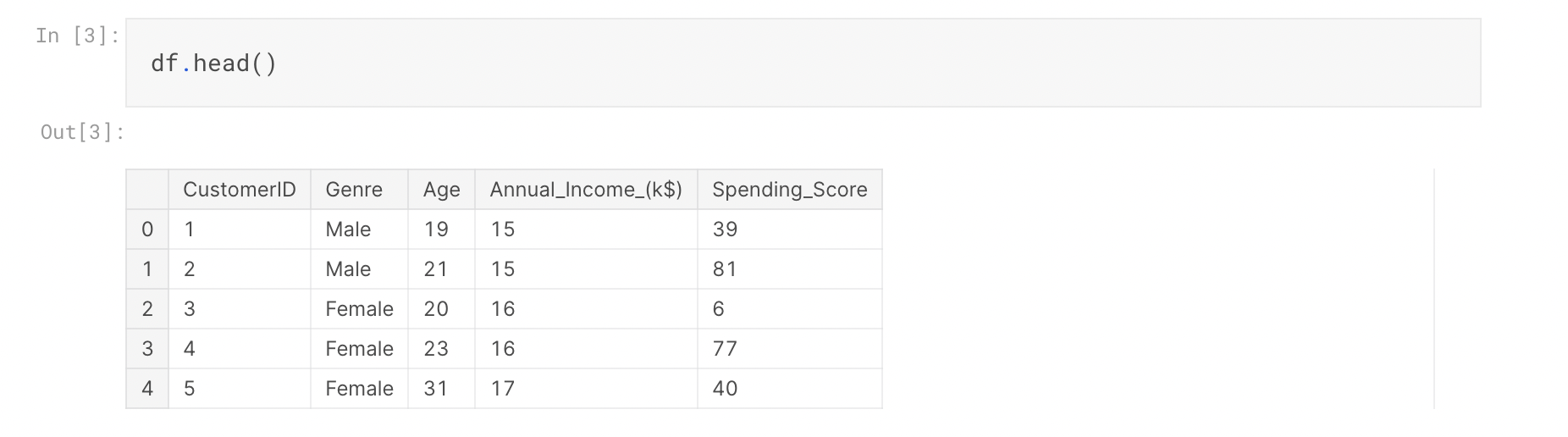
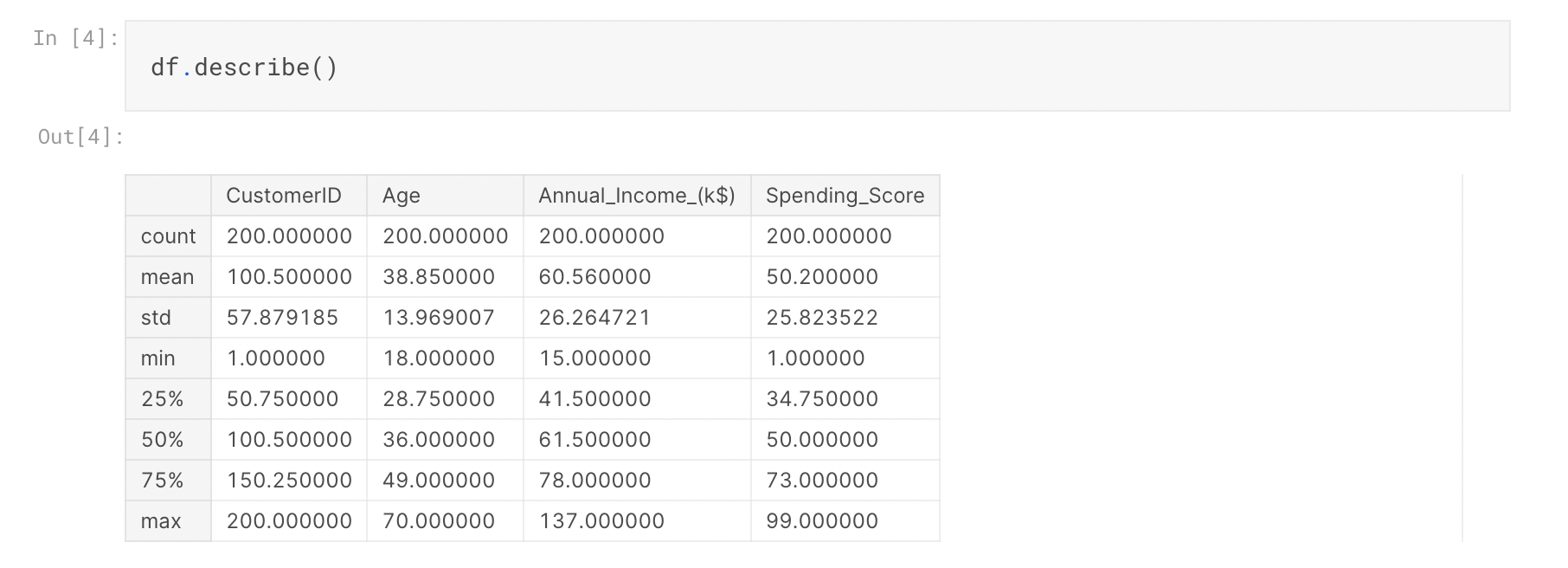
データが200個あり、平均年齢は38.85歳で、平均年収は$60,560(日本円換算で8,165,395円)ということがわかります。
欠損値がないか確認してみます
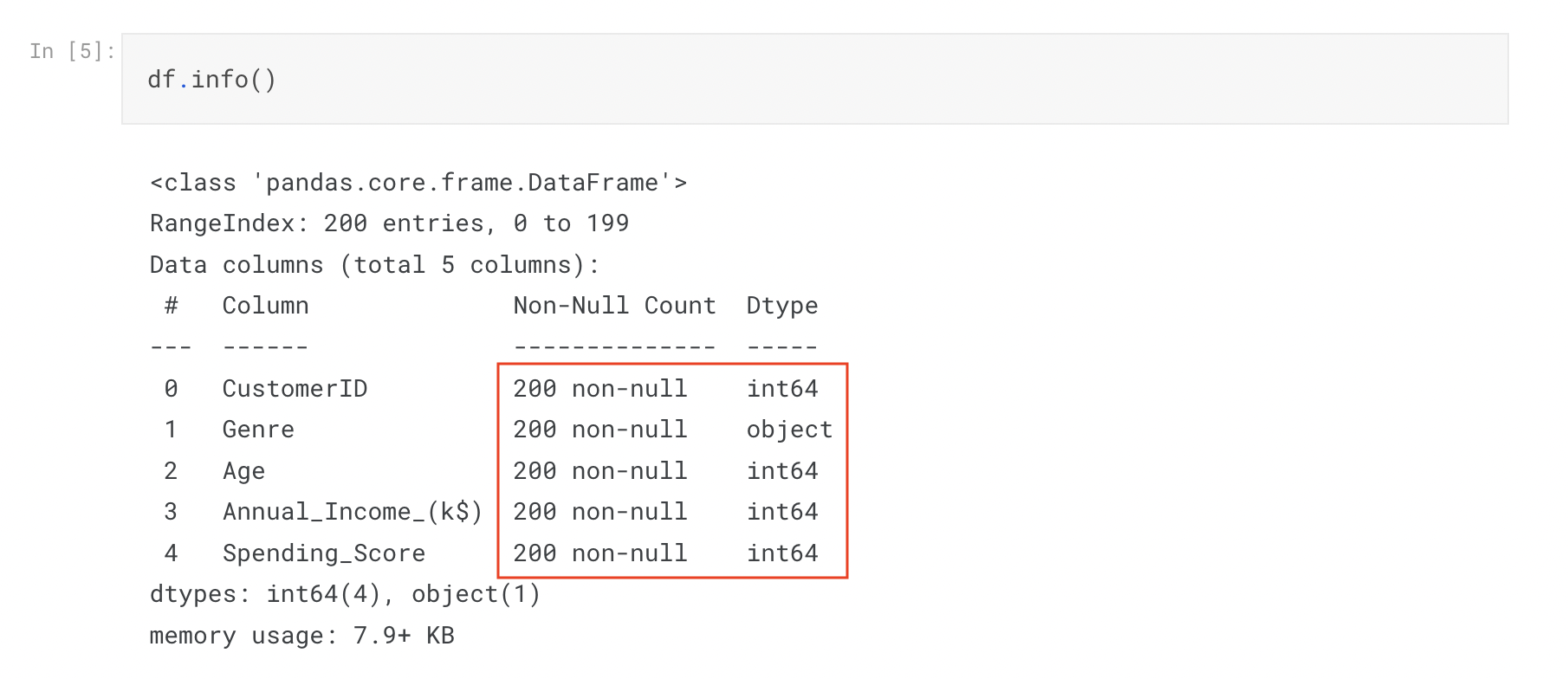
Non-nullなので、欠損値がないことがわかります。性別(Genre)は、データタイプがObjectです。文字データをそのまま学習させるとエラーになる場合があるので、データの型の変換が必要となることがありそうです。
「.corr()」関数を使用して相関関係を見つけてみます
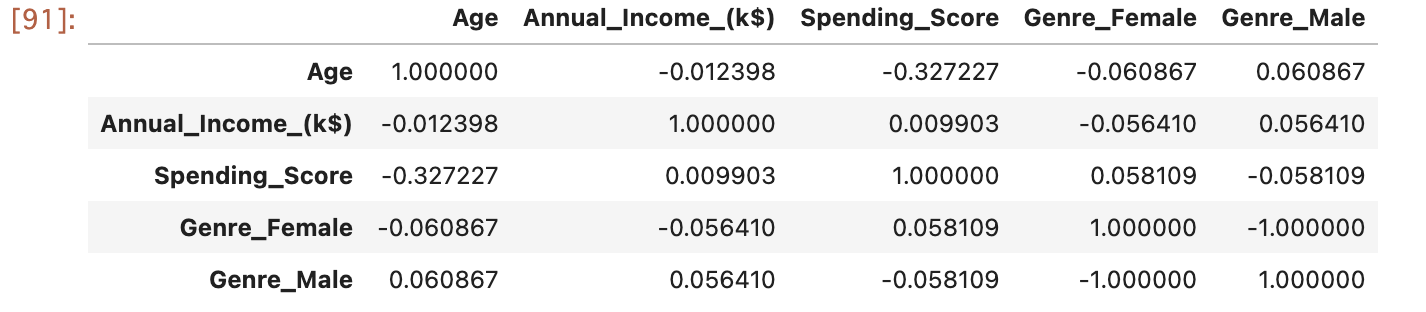
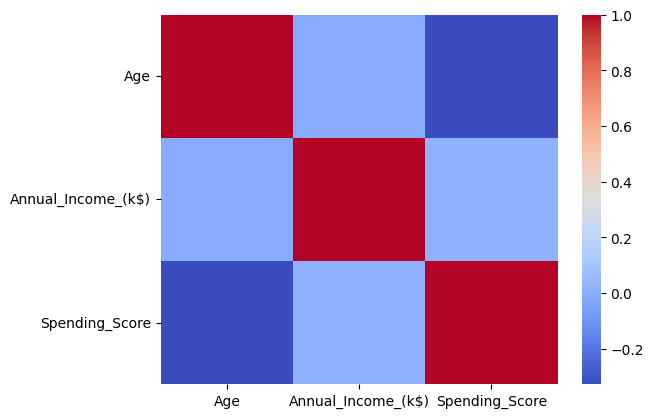
もし大量にデータカラムがある場合はヒートマップにするのもいいでしょう。
最初の予想では、年収と支出スコアに相関があると思いましたが、弱い相関であることがわかります。まだ、年齢と支出スコアの方が強い相関であることが示されています。
相関について
相関係数が1に近づくほど、2つの変数の間には正の強い線形関係があることを示し、一方、相関係数が-1に近づくほど、2つの変数の間には負の強い線形関係があることを示します。相関係数が0に近い場合、2つの変数の間には線形関係がほとんどないことを示します。ただし、2つの変数に非線形な関係がある場合は、相関係数が0に近くても、それらの変数には依然として関係がある可能性があります。
年収と支出スコアに相関があるのではという予想が外れてしまいました。このデータセットにはどのような構造やパターンがあるのでしょうか。
気を取り直して、全体的に把握してみます
複数種類の軸をsubplot(サブプロット)します。
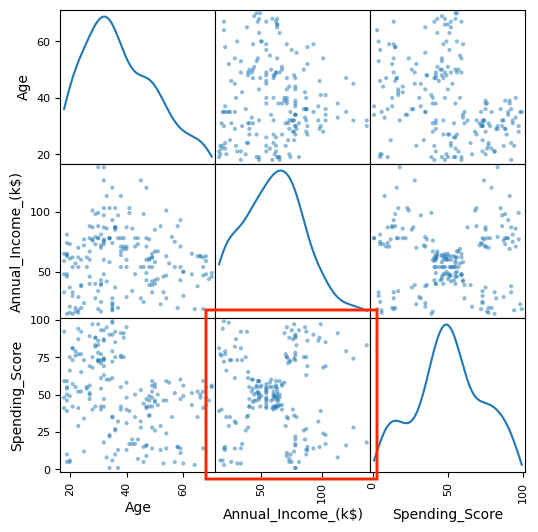
とても特徴的なグラフがありました。拡大してみましょう。
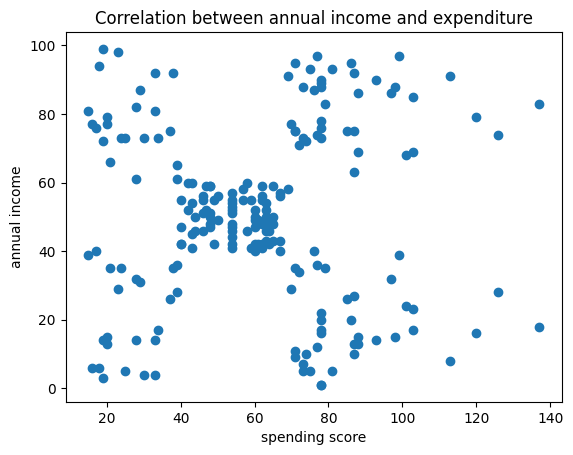
相関はなかったですが、支出スコアは5つに分類できそうです。
クラスタリングしてみます
クラスタリングはKmeansと凝集型クラスタリングという分析手法を使って確認してみましょう。
まずは最適なクラスタリングの数を調べてみました。エルボー法は、k-meansクラスタリングの最適なクラスター数を決定するための手法です。
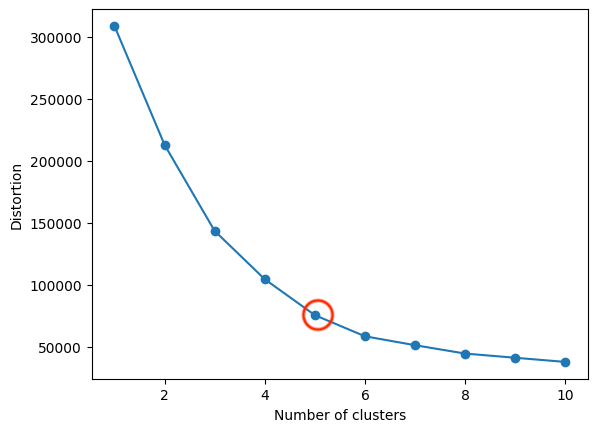
クラスタリングの数は5つで良さそうです。
グラフの曲線が急激に変化する部分を見つけます。この変化の急激な部分をエルボーと呼び、最適なクラスター数として選択されます。
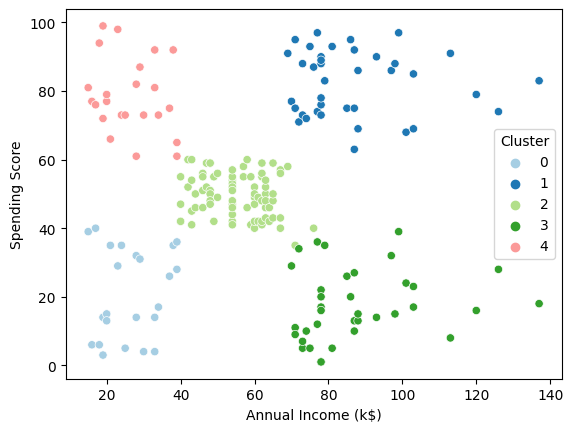
K-meansで分類してみます
K-meansは、クラスタリングのアルゴリズムの一つで、与えられたデータを指定した数のクラスタに分類する手法です。各データポイントを最も近い中心点に割り当てることによって、指定されたクラスタ数でデータを分割します。(この手法では、クラスタの形状が球状であることを仮定しており、非球状のクラスタの分割には向いていません)
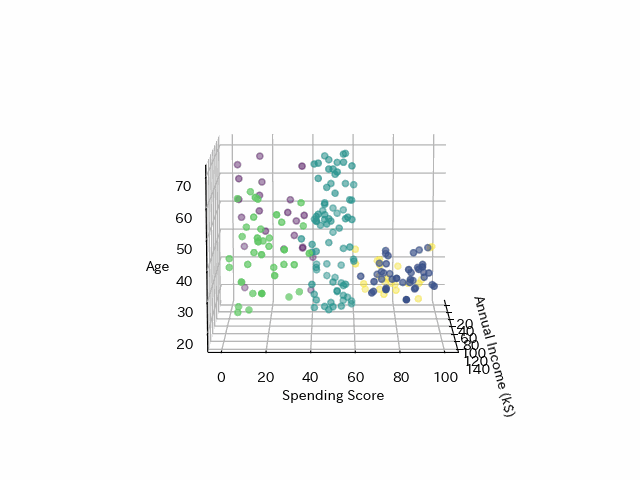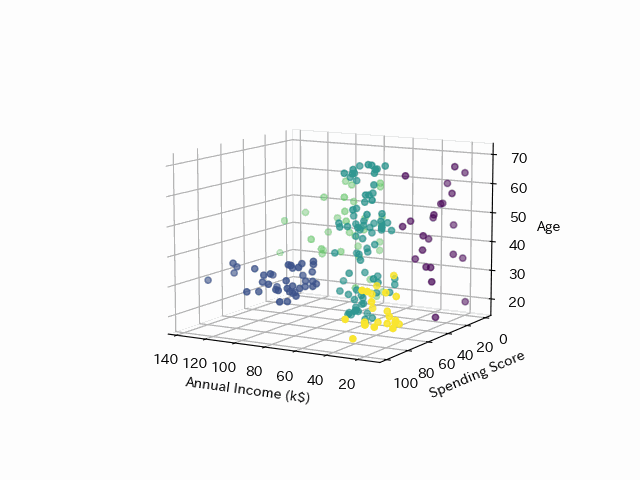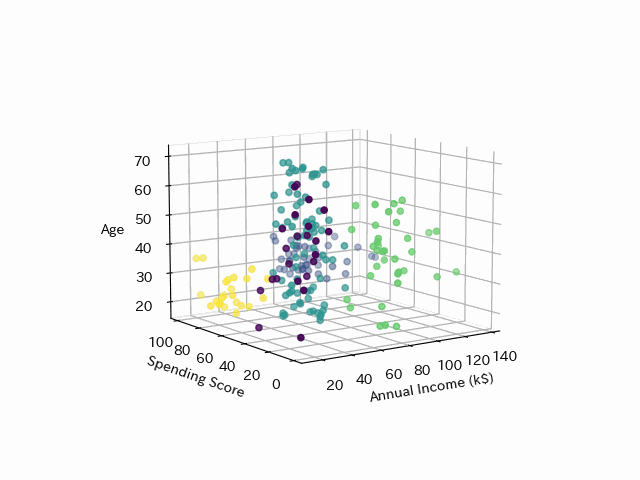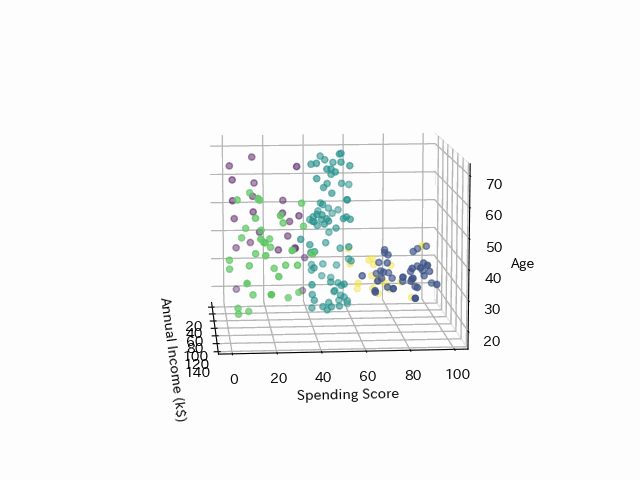
さらに年齢も加えてみてみます
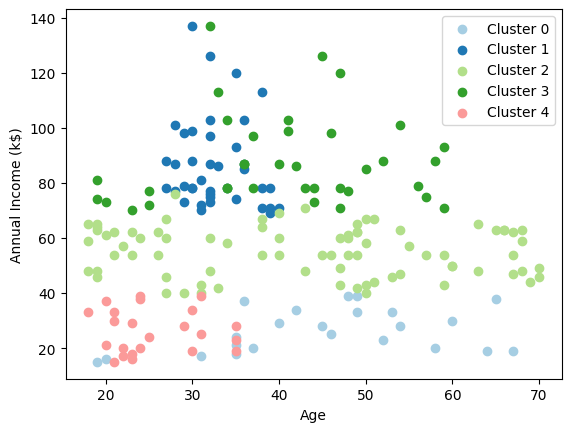
年齢とクラスタリングは関係がありそうです。
Cluster0→年収(低)・支出(低)=稼がず使わず
Cluster1→年収(高)・支出(高)=稼いで使う
Cluster2→年収(中)・支出(中)=真ん中
Cluster3→年収(高)・支出(低)=稼いで使わず
Cluster4→年収(低)・支出(高)=稼いでないけど使う
性別も加えてみてみます
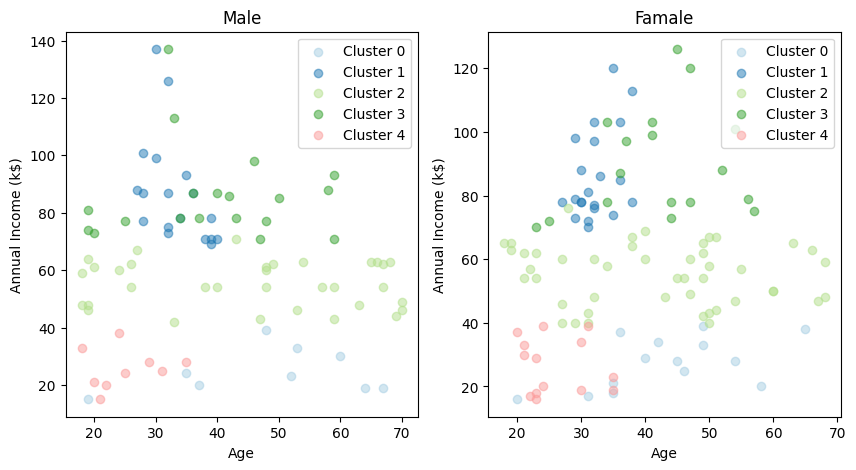
大きな違いは無さそうです。
最後に凝集型クラスタリングでも確認してみます
階層的な手法で、最初に全てのデータポイントを個別のクラスタとし、その後、類似度の高いクラスタを結合していくことでクラスタを形成していきます。
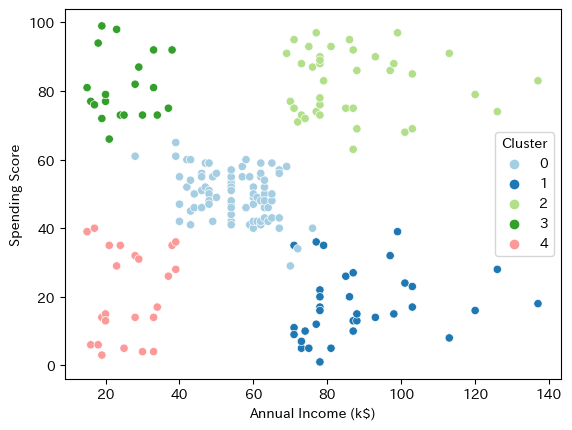
大きく変わらないですね。
もし、目的変数を支出スコアとした場合、当初は収入と支出スコアの相関関係を予測し、回帰直線で表すことができ、年収から支出スコアを予測することができるのではないかと考えました。しかし、EDA(データの探索)により視覚化することで5つに分類でき、クラスターの性格は年齢も影響しているということがわかりました。
最後にK-meansのクラスタリングを年齢と年収、支出スコアのx,y,z軸でプロットし、3DにしたGifアニメーションです。これもpythonで作れます!