画像生成AI Stable Diffusion Web UIの追加学習データの利用(動画あり)
今回はすでにインストールし、より面白い使い方ができないかと考えている方に向けて、デフォルト機能からの拡張方法を紹介します。実際にカスタムモデルをインストールし、画像をアニメ風イラストへ変換した動画も用意しました。
参考にしてみてください。
Model、Lora、Embeddingなどの追加学習データを利用する
Stable Diffusion Web UIでは、モデル、LoRA、Embeddingなどの追加学習データを利用することで、画像生成の可能性をさらに広げることができます。
1.カスタムモデルで表現の幅を広げる
デフォルトモデルに加え、カスタムモデルを使用することで、様々な画風やテーマを表現できます。
使い方
Hugging Faceから好きなモデルをダウンロード
Stable Diffusion Web UIのmodelsフォルダに配置
Web UIの画面右上のモデル選択ドロップダウンから追加したモデルを選択
2. LoRA (Latent space Of Rendered Animations)でディテールを追求する
LoRAは、画像生成におけるノイズの形状を制御する技術です。Loraファイルを導入することで、特定の要素を強調したり、細部を調整したりすることができます。
使い方
LoRAファイルをダウンロード(Civitaiは、AIモデル、LoRA、VAEをダウンロードできます
Stable Diffusion Web UIのLoRAフォルダに配置
Web UIのLoRAタブで追加したファイルを選択(Lora Strengthスライダーで適用強度を調整)
Prompt欄にLoRAファイル名が入力される
Anime eyesは 目の表現を強化し、よりアニメ風な瞳を生成。epi_noiseoffset2 は、コントラストが向上し、画像が暗くなるため、夜の雰囲気を出すことに向いています。
3.Embeddingで意図を明確に伝える
Embeddingは、テキスト情報を数値に変換する技術です。Embeddingファイルを使用することで、Stable Diffusion Web UIに伝えたい意図をより明確に伝えることができます。
使い方
Embeddingファイルをダウンロード
Stable Diffusion Web UIのembeddingsフォルダに配置
Web UIのEmbeddingタブで追加したファイルを選択
Prompt欄にEmbeddingファイル名が入力される
例えば、ng_deepnegative_v1_75t.pt は、不完全な人体構造、不快な配色、逆さまの空間構造などを含む、不快な構成や色のパターンが何であるかを学習しています。ネガティブプロンプトに入れて効果を発揮します。
4. ESRGANで高解像度化を実現
ESRGANは、画像の解像度を向上させる技術です。生成した画像をESRGANで処理することで、より高精細な画像を得ることができます。
使い方
ESRGANのGUIツールをインストール
models/ESRGANフォルダに配置
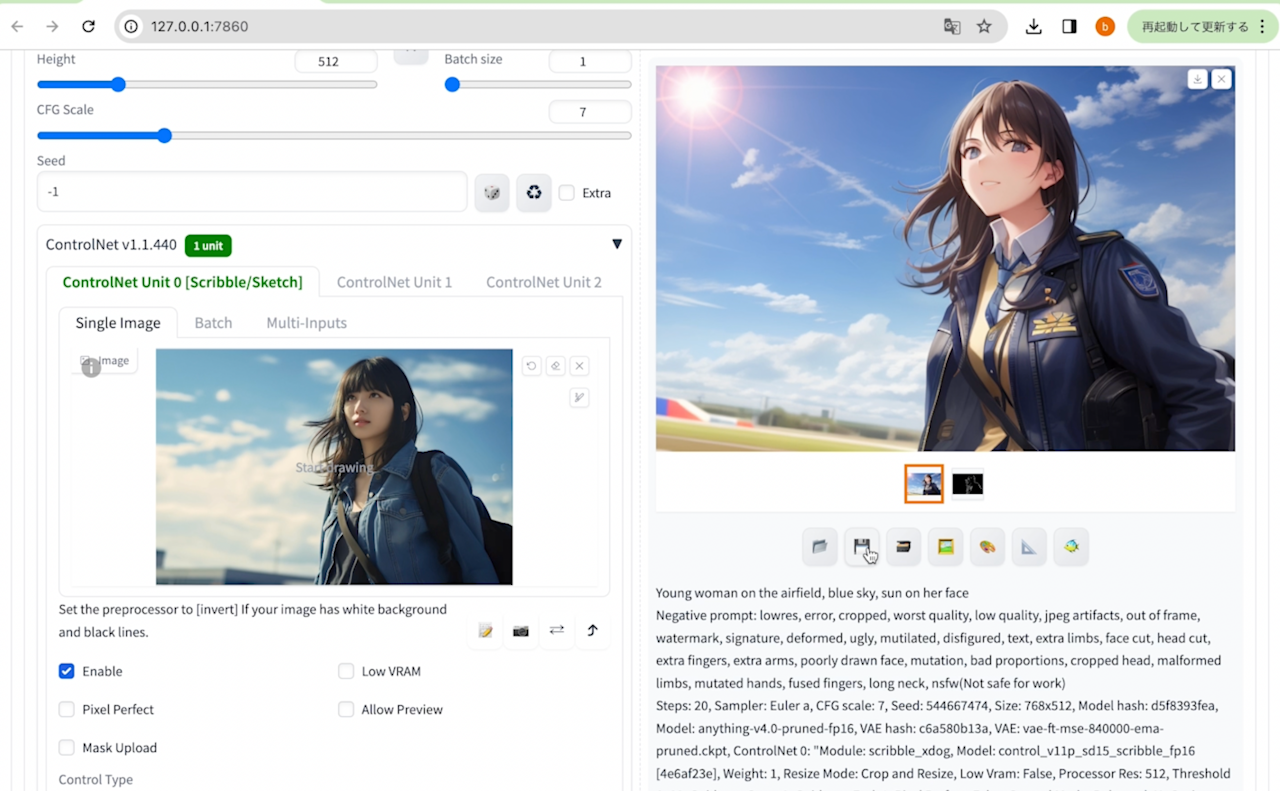
カスタムモデルを使用して実写をアニメ風のイラストへ
今回利用したモデルは、Anything V4.0です。
Stable Diffusion Web UI を起動させる
Hugging Faceを開く
Anything V4.0の軽量モデルであるanything-v4.0-pruned-fp16.safetensorsをダウンロード
stable-diffusion-webui/models/Stable-diffusionフォルダに移動させる
GUIからAnythingを選択する
すでにインストールしたControlNetを使って画像を線画化する
どのsamplerがいいのか評価してみる
Euler aが良かったので、Euler aをもう少し調整してみる
次回、時間がある時には下記のようなものも試してみたいと思います。
キャラクターのポーズを制御する
照明を当てる
ストリートビューを変更する
線画をデザインする
元素材は自分で用意することでオリジナルのコンテンツが、AIを楽しみながらできました。プロンプトだけの制御では、イメージした画像を作成することは非常に難しい作業になります。プロンプトには、アーティスト名を入力しないことが倫理的には重要と感じます。
また、高性能のAI Art Softwereを使って、作るものをイメージができてない人が適当に使って、良い効果を出すことは難しいと感じます。
AIを活用したクリエイティブのご相談お待ちしております!




